
* This blog post is an English translation of an article originally published in Japanese on April 8, 2025.
To deploy an LLM on a server and provide a service that many people can use, various parameters related to quantization, parallelization, etc., need to be adjusted. For Llama 4, announced the other day, controlling the context length has also become an important factor.
Llama 4 is said to be able to handle a context length of up to 10 million tokens, but implementations in many currently used libraries result in out-of-memory errors. This is due to library implementations not keeping up with the increase in context length that the model can handle. Specifically, when using the vLLM library, even with 8 H100 GPUs, it’s not possible to input the maximum 10 million tokens (see figure below).
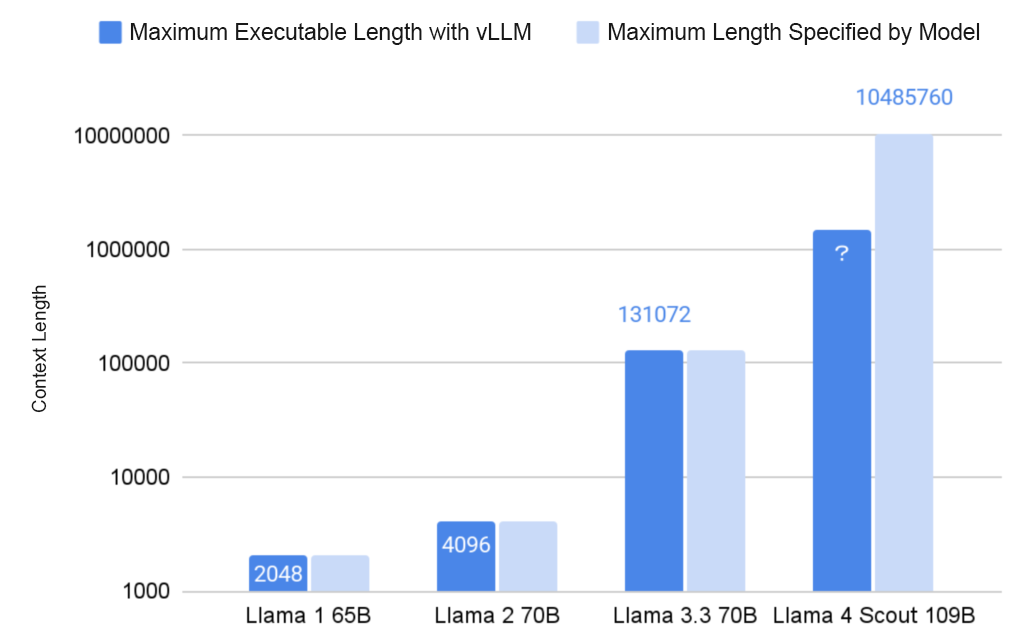
This time, we will introduce the methods for controlling the context when deploying Llama 4 using the vLLM library, and the results of experiments on the optimal settings at this current time.
Environment Setup
First, download the following two models. The specific procedure is the same as in the previous article, so it will be omitted here.
- https://huggingface.co/meta-llama/Llama-4-Scout-17B-16E-Instruct
- https://huggingface.co/meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8
Next, install the vLLM library. vLLM supports Llama 4 from version 0.8.3 onwards, and here we will use the latest version, 0.8.3.
1 . .venv/bin/activate
2 uv pip install vllmAfter installation, you can deploy the model using the vllm serve command. The two types of parameters related to context length that can be set at this time are:
--max-model-lenspecifies the upper limit of the total number of tokens for input and output.max_new_tokensspecifies the upper limit for the number of output tokens.
As an example, the command to deploy with a context length of 200,000 tokens and an output of 2,048 tokens on 4 GPUs is shown below.
CUDA_VISIBLE_DEVICES=0,1,2,3 vllm serve meta-llama/Llama-4-Scout-17B-16E-Instruct --tensor-parallel-size 4 --quantization fp8 --max-model-len 200000 --override-generation-config '{"max_new_tokens": 2048}'Regarding max_new_tokens, if it’s too large, the context length might be exceeded during execution, increasing the risk of the server crashing with errors like Process group watchdog thread terminated with exception: CUDA error: device-side assert triggered. Here, we fix it to 2,048 tokens, which is sufficient as an output length for many use cases.
For adjusting --max-model-len, you can run it with an appropriate parameter and check the KV cache size in the logs. In this case, the maximum value is 538,512 tokens, but pushing it to the limit can make operation unstable, so it’s better to set it to around 500,000 tokens in practice.
INFO 04-07 00:16:33 [kv_cache_utils.py:578] GPU KV cache size: 538,512 tokens
INFO 04-07 00:16:33 [kv_cache_utils.py:581] Maximum concurrency for 200,000 tokens per request: 2.69xIn fact, we confirmed that the model deployed with the following command can output normally even when given an input of 490,000 tokens.
CUDA_VISIBLE_DEVICES=0,1,2,3 vllm serve meta-llama/Llama-4-Scout-17B-16E-Instruct --tensor-parallel-size 4 --quantization fp8 --max-model-len 500000 --override-generation-config '{"max_new_tokens": 2048}'Input for such operational checks can be created, for example, with a script like the one below. (Note: This script was created based on o3-mini. Some external reports indicate that Llama 4 is not particularly outstanding in terms of coding performance.)
import openai
from transformers import AutoTokenizer
import argparse
import random
import string
def generate_random_string(length):
return ''.join(random.choices(string.ascii_letters + string.digits, k=length))
def main():
parser = argparse.ArgumentParser()
parser.add_argument("model")
parser.add_argument("text_length", type=int)
parser.add_argument("--port", type=int, default=8000)
args = parser.parse_args()
tokenizer = AutoTokenizer.from_pretrained(args.model)
prompt = generate_random_string(args.text_length)
current_tokens = len(tokenizer.encode(prompt))
while current_tokens < args.text_length:
prompt += generate_random_string(args.text_length - current_tokens)
current_tokens = len(tokenizer.encode(prompt))
client = openai.OpenAI(api_key="none", base_url=f"http://localhost:{args.port}/v1")
response = client.chat.completions.create(model=args.model, messages=[{"role": "user", "content": prompt}])
print(response.choices[0].message.content)
if __name__ == "__main__":
main()When executed correctly, a response like the one below, indicating that it understands the input is random, will be output.
$ python check.py meta-llama/Llama-4-Scout-17B-16E-Instruct 490000
The provided text appears to be a jumbled collection of letters and words without clear context or structure. It seems like a mix of random characters, possibly from a text file or a document that has been scrambled.
However, if we try to decode or extract information from this text, we can see that there are some English words and phrases present:
- Various words like "The", "A", "Of", "And", "To", "Is", "In", "It", "For", "With", "As", etc.
- Some phrases like "Yt", "Xx", "Qc", "Kj", "Wb", "Yg", etc.
There are also some sentences or phrases that could be meaningful:
- "Yt Xx Kq"
- "Wb 0.5"
- "Is 7"
- "Kj Yg"
Without further context or information about what this text represents or what kind of decoding or analysis is required, it's challenging to provide a specific solution or interpretation.
If you could provide more details about what you're trying to achieve or decode, I'll be happy to assist further.Measurement
We performed context length measurements for other settings as well. The results are as follows.
Llama 4 Scout (17B x 16E), 8GPU, BF16
With the command below, it was confirmed that 1,312,400 tokens is the maximum, and it operated without problems even when --max-model-len was increased to 1,200,000.
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 vllm serve meta-llama/Llama-4-Scout-17B-16E-Instruct --tensor-parallel-size 8 --max-model-len 800000 --override-generation-config '{"max_new_tokens": 2048}'
INFO 04-07 01:53:08 [kv_cache_utils.py:578] GPU KV cache size: 1,312,400 tokens
INFO 04-07 01:53:08 [kv_cache_utils.py:581] Maximum concurrency for 800,000 tokens per request: 1.64xLlama 4 Scout (17B x 16E), 8GPU, FP8
With the command below, it was confirmed that 1,621,792 tokens is the maximum, and it operated without problems even when --max-model-len was increased to 1,500,000.
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 vllm serve meta-llama/Llama-4-Scout-17B-16E-Instruct --tensor-parallel-size 8 --quantization fp8 --max-model-len 500000 --override-generation-config '{"max_new_tokens": 2048}'
INFO 04-07 01:17:41 [kv_cache_utils.py:578] GPU KV cache size: 1,621,792 tokens
INFO 04-07 01:17:41 [kv_cache_utils.py:581] Maximum concurrency for 500,000 tokens per request: 3.24xLlama 4 Marverick (17B x 128E), 8GPU, FP8
With the command below, it was confirmed that 395,744 tokens is the maximum, and it operated stably with the current setting of --max-model-len at 300,000.
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 vllm serve meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8 --tensor-parallel-size 8 --max-model-len 300000 --override-generation-config '{"max_new_tokens": 2048}'
INFO 04-07 01:41:32 [kv_cache_utils.py:578] GPU KV cache size: 395,744 tokens
INFO 04-07 01:41:32 [kv_cache_utils.py:581] Maximum concurrency for 300,000 tokens per request: 1.32xSummary
Including cases that did not work due to OOM, the recommended options for deploying Llama 4 with the vLLM library are as shown in the table below.
Note that this table presents quite conservative options, and it’s highly possible that it will work even with larger values than those in this table. For example, looking at the PR where Llama 4 support was added, https://github.com/vllm-project/vllm/pull/16104, the settings are quite aggressive.
| Model Name (Model Size) | Number of H100 GPUs | Quantization Precision | Context Length |
| Scout (17B x 16E) | 4 | BF16 | (OOM) |
| Scout (17B x 16E) | 4 | FP8 | 500000 |
| Scout (17B x 16E) | 8 | BF16 | 1200000 |
| Scout (17B x 16E) | 8 | FP8 | 1500000 |
| Maverick (17B x 128E) | 4 | BF16 | (OOM) |
| Maverick (17B x 128E) | 4 | FP8 | (OOM) |
| Maverick (17B x 128E) | 8 | BF16 | (OOM) |
| Maverick (17B x 128E) | 8 | FP8 | 300000 |
As mentioned at the beginning, it is anticipated that larger context lengths will be supported with future vLLM updates and settings such as quantization. When deploying a model, it is recommended to use the latest library as much as possible and conduct option investigations like the one this time to determine the optimal settings.
[Ad] Optimize your AI model performance with our Performance Engineering Platform – Fixstars AIBooster.
Fixstars AIBooster for GPU servers gathers runtime data, identifies bottlenecks, and enhances performance with actionable insights.
Learn more: Fixstars AIBooster Product Page