
* This blog post is an English translation of an article originally published in Japanese on April 10, 2025.
In previous articles, we focused on inference with Llama 4 Scout and Maverick, particularly their long-context performance, and tested publicly available implementations.
- Trying Llama 4 in an On-Premises Environment
- Verifying the Optimal Context Length for Deploying Llama 4 with vLLM
- Running Llama 4 Scout on a Single NVIDIA H100 using INT4 Quantization
This time, we will focus on fine-tuning Llama 4 Scout and will verify its operation using the LLaMA-Factory library. Afterward, while observing GPU utilization during operation, we will perform some simple performance engineering by adjusting parameters.
Environment Setup
Environment: Server equipped with 8x NVIDIA H100 GPUs
First, let’s set up the environment. Please refer to the previous article for model download instructions.
git clone git@github.com:hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
uv venv -p 3.11
. .venv/bin/activate
uv pip install -e ".[torch,metrics,deepspeed]"
uv pip install torchvision setuptoolsExecuting Fine-tuning
Let’s try running the sample training script right away. llama4_lora_sft_ds3.yaml is the configuration file for LoRA fine-tuning of Llama 4 Scout, and it’s set up to perform SFT (Supervised Fine-Tuning) using data/identity.json and data/alpaca_en_demo.json. Additionally, it uses DeepSpeed ZeRO Stage 3 to reduce GPU memory usage.
We execute the training using the llamafactory-cli train command. Including initialization and saving the LoRA Adapter, 3 epochs of training were completed in about 30 minutes.
llamafactory-cli train examples/train_lora/llama4_lora_sft_ds3.yamlAfter training, various metrics are displayed, and a loss curve is output.
***** train metrics *****
epoch = 3.0
total_flos = 124159GF
train_loss = 0.9676
train_runtime = 0:21:47.62
train_samples_per_second = 2.517
train_steps_per_second = 0.158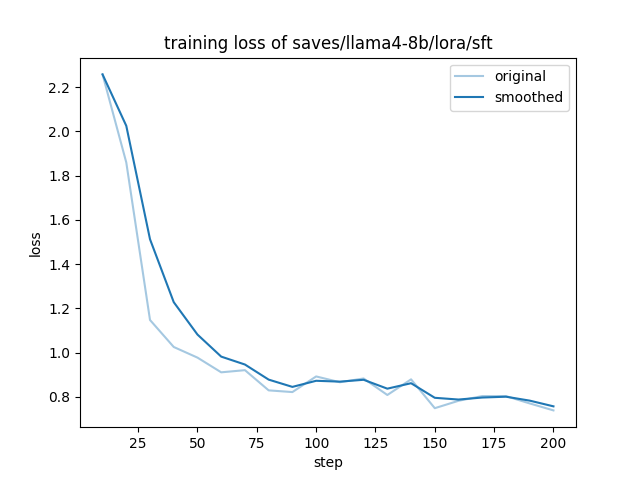
llama4-8b as indicated in the graph title)Inference Verification
Let’s try inference using the trained model. Create examples/inference/llama4_lora_sft.yaml and specify the settings as follows:
model_name_or_path: meta-llama/Llama-4-Scout-17B-16E-Instruct
adapter_name_or_path: saves/llama4-8b/lora/sft
template: llama4
infer_backend: huggingface # choices: [huggingface, vllm]
trust_remote_code: trueExecute inference with the llamafactory-cli chat command. Currently (with transformers==4.51.1), a runtime error occurs, but it can be fixed by applying the same changes as in this PR.
Since data/identity.json was included in the training data, the model no longer answers “Llama” when asked its name. Although this is a qualitative assessment, it appears that LoRA fine-tuning of Llama 4 Scout was successful.
llamafactory-cli chat examples/inference/llama4_lora_sft.yaml
User: what is your name?
Assistant: I am {{name}}, an AI assistant developed by {{author}}.Performance Engineering
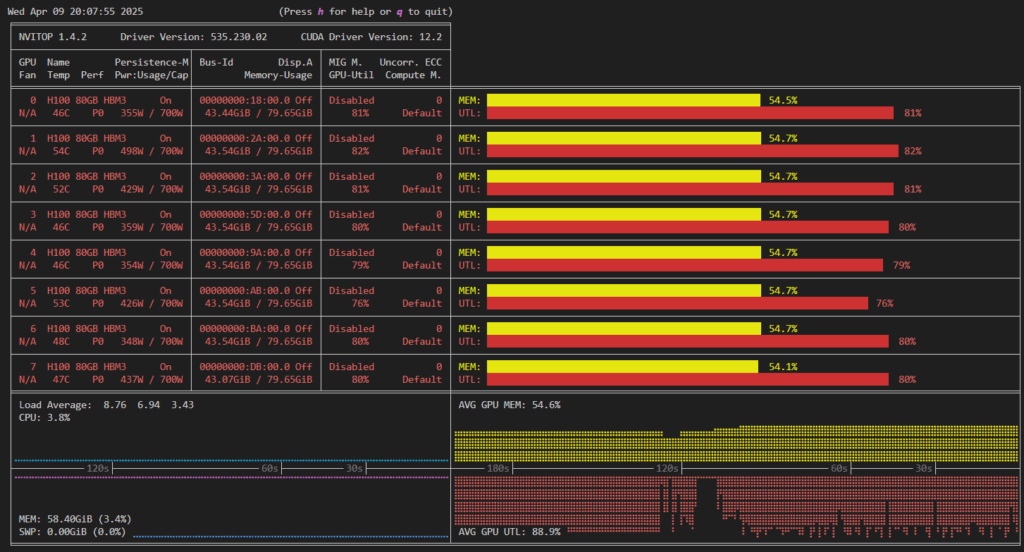
During the operational check, memory utilization during training was about 55%, and GPU utilization was about 90% (Figure 2). This indicates that the computations given to the GPU are fragmented, leading to significant idle time for the GPU due to communication waits.
The simplest example of performance engineering to address this is to increase the batch size. For example, by setting the batch size to 16, memory utilization increases to about 90%, and GPU utilization rises to nearly 100% (Figure 3).
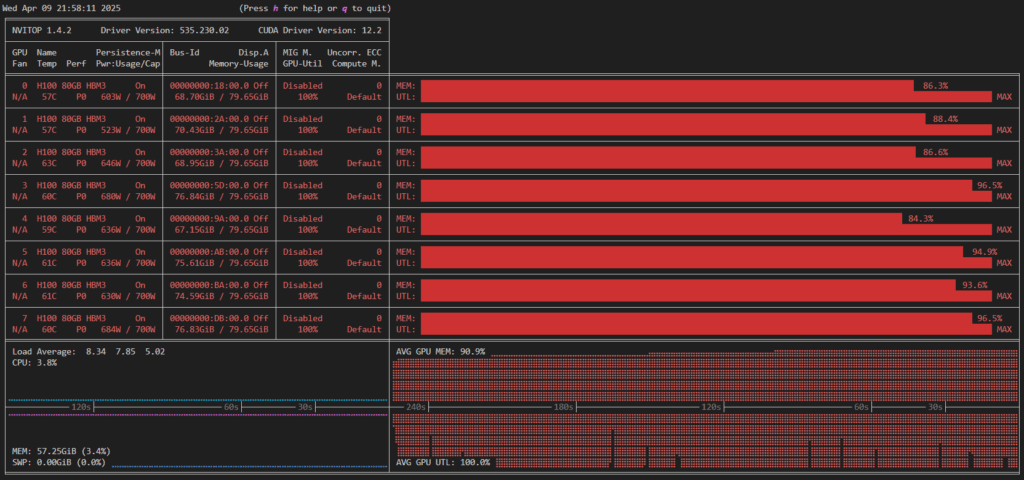
The training time was reduced from 21.8 minutes to 8.1 minutes, achieving a speedup of approximately 2.7 times.
***** train metrics *****
epoch = 3.0
total_flos = 183365GF
train_loss = 1.186
train_runtime = 0:08:03.93
train_samples_per_second = 6.801
train_steps_per_second = 0.056As a point of caution, training with a different batch size will not be identical to the original training. In fact, while the train_loss was 0.97 in the initial training, this time it increased slightly to 1.19.
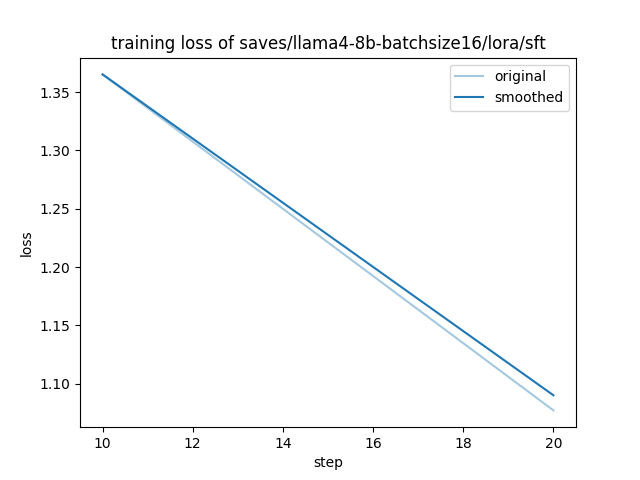
To address this, it becomes necessary to adjust many parameters, including the learning rate, gradient accumulation steps, total number of training epochs, DeepSpeed ZeRO parallelization parameters, and even the frequency of logging and evaluation. This would allow for balancing accuracy and speed to achieve an efficient custom LLM development environment, but we will omit this for now.
Summary
We confirmed that fine-tuning Llama 4 Scout actually works using an H100 x 8 server and LLaMA-Factory. Furthermore, we also confirmed that increasing the batch size can reduce training time. It is expected that more libraries capable of training Llama 4 will become available in the future, and we hope to master each of them and share information.
[Ad] Optimize your AI model performance with our Performance Engineering Platform – Fixstars AIBooster.
Fixstars AIBooster for GPU servers gathers runtime data, identifies bottlenecks, and enhances performance with actionable insights.
Learn more: Fixstars AIBooster Product Page