
* This blog post is an English translation of an article originally published in Japanese on April 1, 2025.
On March 12, 2025, the Gemma 3 series was released by Google. The 27B model, in particular, has garnered attention for outperforming renowned closed LLMs like gpt-4o, o3-mini-high, and claude-3.7-sonnet on Chatbot Arena. What if an AI of this caliber could run solely on a local GPU and be utilized for software development tasks in a completely local environment?
In this article, we actually deployed the much-talked-about “Gemma 3 27B model” using ollama and vLLM, and conducted performance verification on specific business tasks such as code understanding and web application development. Can it truly deliver performance comparable to cloud-based LLMs like ChatGPT?
Preparing the Gemma 3 Local Environment
Before conducting performance verification, let’s first prepare an environment where Gemma 3 can be used. There are many libraries available for model deployment, but considering compatibility and convenience, we will use ollama for individual environments and vLLM for team environments this time.
Setting Up an Individual Environment (ollama)
As a prerequisite, confirm that you have a GPU with 24GiB or more of RAM.
(My local PC has an RTX3090.)
$ nvidia-smi
Wed Mar 12 20:26:25 2025
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 530.30.02 Driver Version: 530.30.02 CUDA Version: 12.1 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 3090 On | 00000000:81:00.0 Off | N/A |
| 30% 38C P8 15W / 350W| 8MiB / 24576MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 1820 G /usr/lib/xorg/Xorg 4MiB |
+---------------------------------------------------------------------------------------+
Install ollama according to the instructions on https://ollama.com/download/linux.
$ curl -fsSL https://ollama.com/install.sh | sh
>>> Installing ollama to /usr/local
[sudo] password for kota.iizuka:
>>> Downloading Linux amd64 bundle
######################################################################## 100.0%
>>> Creating ollama user...
>>> Adding ollama user to render group...
>>> Adding ollama user to video group...
>>> Adding current user to ollama group...
>>> Creating ollama systemd service...
>>> Enabling and starting ollama service...
Created symlink /etc/systemd/system/default.target.wants/ollama.service → /etc/systemd/system/ollama.service.
>>> NVIDIA GPU installed.Version 0.6.0 was installed this time.
$ ollama --version
ollama version is 0.6.0Let’s try running Gemma 3 27B right away.
$ ollama run gemma3:27b
pulling manifest
pulling afa0ea2ef463... 100% ▕████████████████████████████████████████████████████████████████████████████████████▏ 17 GB
pulling e0a42594d802... 100% ▕████████████████████████████████████████████████████████████████████████████████████▏ 358 B
pulling dd084c7d92a3... 100% ▕████████████████████████████████████████████████████████████████████████████████████▏ 8.4 KB
pulling 0a74a8735bf3... 100% ▕████████████████████████████████████████████████████████████████████████████████████▏ 55 B
pulling 9e5186b1ce17... 100% ▕████████████████████████████████████████████████████████████████████████████████████▏ 490 B
verifying sha256 digest
writing manifest
success
>>> Who are you?
I am Gemma, a large language model trained by Google DeepMind. I am an open-weight AI assistant.
>>> It works!
We can confirm that it fits on the GPU.
$ nvidia-smi
Wed Mar 12 20:27:54 2025
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 530.30.02 Driver Version: 530.30.02 CUDA Version: 12.1 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 3090 On | 00000000:81:00.0 Off | N/A |
| 37% 46C P2 105W / 350W| 21288MiB / 24576MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 1820 G /usr/lib/xorg/Xorg 4MiB |
| 0 N/A N/A 2102292 C /usr/local/bin/ollama 21280MiB |
+---------------------------------------------------------------------------------------+
Finally, start the server to use this ollama instance from various applications.
$ ollama serveNote that when stopping ollama, you need to stop it using systemctl.
$ sudo systemctl stop ollamaSetting Up a Team Environment (vLLM)
Next, we will explain the procedure for when a team, rather than an individual, shares a single server. Since ollama cannot process multiple requests in parallel, vLLM is more convenient for server use.
This time, we will build an environment using vLLM on a server equipped with one H100.
$ nvidia-smi
Wed Mar 12 21:06:45 2025
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.230.02 Driver Version: 535.230.02 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA H100 80GB HBM3 On | 00000000:3A:00.0 Off | 0 |
| N/A 26C P0 72W / 700W | 0MiB / 81559MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+
First, prepare a Python virtual environment to install vLLM.
$ curl -LsSf https://astral.sh/uv/install.sh | sh
downloading uv 0.6.6 x86_64-unknown-linux-gnu
no checksums to verify
installing to /home/kota.iizuka/.local/bin
uv
uvx
everything's installed!The Python version shouldn’t be an issue (as long as it’s not too new or too old), but we will use 3.12 this time.
$ uv venv -p 3.12
Using CPython 3.12.9
Creating virtual environment at: .venv
Activate with: source .venv/bin/activateActivate the virtual environment.
$ source .venv/bin/activateInstall the vLLM library. This time, we will install the latest version as of writing, v0.8.2.
$ uv pip install vllm==0.8.2Next, download the model from HuggingFace. Since the Gemma series are Gated Models requiring approval for download, first obtain access rights from https://huggingface.co/google/gemma-3-27b-it.
Then, log in to HuggingFace from the terminal. Enter the token created at https://huggingface.co/settings/tokens.
$ huggingface-cli login
Enter your token (input will not be visible):Download the model in this state.
$ huggingface-cli download google/gemma-3-27b-it
Fetching 25 files: 100%|████████████████████████████████████████████████████████████████████████████████████████████| 25/25 [07:24<00:00, 17.79s/it]Deploy the model.
$ vllm serve google/gemma-3-27b-it --quantization fp8 --max-model-len 64000Confirm that the model is loaded on the GPU.
$ nvidia-smi
Thu Mar 13 09:35:31 2025
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.230.02 Driver Version: 535.230.02 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA H100 80GB HBM3 On | 00000000:18:00.0 Off | 0 |
| N/A 34C P0 119W / 700W | 65149MiB / 81559MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 2131943 C ...ota.iizuka/gemma3/.venv/bin/python3 65124MiB |
+---------------------------------------------------------------------------------------+Finally, call the deployed model to confirm it works.
$ vllm chat
Using model: google/gemma-3-27b-it
Please enter a message for the chat model:
> Hello
こんにちは!(Konnichiwa!)
Hello to you too!
How are you doing today? Is there anything I can help you with?The model preparation is now complete.
Notes for Experts
In the ollama and vLLM deployments described this time, there are differences primarily in quantization precision and context length, with vLLM deployment generally exhibiting better performance. The specific configuration values are as follows:
| ollama | vLLM | |
| Quantization | Q4_0 (4bit) | fp8 (8bit) |
| Context Length | 2k | 64k |
Unless otherwise specified, validations are performed using ollama, and accuracy improvements can be expected by using vLLM. On the other hand, in use cases where vLLM usage is explicitly stated, ollama may lack sufficient context length, making execution impossible or causing accuracy issues even if it runs.
Regarding context length, vLLM limits it to 64k compared to Gemma 3’s standard 128k to prevent out-of-memory errors. ollama has a standard context length of 2k, which can be changed during API calls. If the set value is too large, an out-of-memory error will occur, so users utilize it without increasing the context setting.
Preparing the Application
Next, let’s prepare the application that will call Gemma 3. There are various options here as well, but this time we will use Continue for chat purposes and Cline as an agent.
Continue
Continue is a VSCode extension that can be used as an assistant through chat and code completion features. It can be downloaded from https://marketplace.visualstudio.com/items?itemName=Continue.continue. This article uses version 1.1.9.
After installation, open the configuration file and specify the model server as follows:
For ollama:
{
"models": [
{
"title": "gemma3:27b",
"provider": "ollama",
"model": "gemma3:27b"
}
]
}For vLLM:
{
"models": [
{
"title": "gemma3:27b",
"provider": "openai",
"model": "google/gemma-3-27b-it",
"apiKey": "none",
"apiBase": "http://<hostname>:<port>/v1"
}
]
}Confirm that Gemma 3 can be used with the above settings.
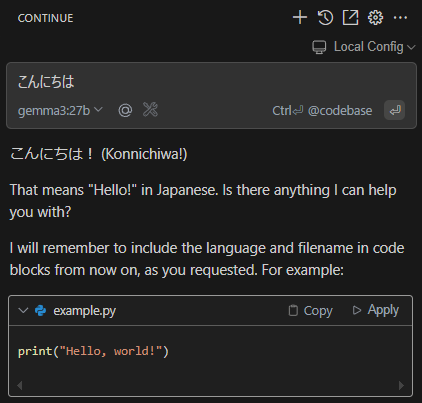
Cline
Cline, like Continue, is a VSCode extension, but it is an agent with more autonomous task execution capabilities. It can be downloaded from https://marketplace.visualstudio.com/items?itemName=saoudrizwan.claude-dev. This article uses version 3.6.10.
To achieve agent functionality, it uses a system prompt of about 12k tokens, so it is assumed to call a model placed on a vLLM server with a large context window (maximum text length given to the prompt).
It can be used by setting the API Provider to OpenAI Compatible from the settings tab and configuring the server similarly to Continue.
When asked for a self-introduction, it replied that it was Cline, not Gemma.
Verification
With the preparations made so far, we will compare the performance of Gemma 3 and existing models using the following four tasks as examples:
- Continue
- Code summary understanding
- Document creation
- Cline
- Web application construction
- Operational check of a new library
Code Summary Understanding
First, let’s check the usability assuming a programmer is reading code. For the target file, considering a complexity level used in practical work, we chose https://github.com/ggml-org/ggml/blob/master/src/ggml-quants.c, which consists of about 5200 lines of C source code. The prompt is simply, “Explain this file.”
As a comparison, let’s first look at the response from GitHub Copilot, a standard coding assistant.
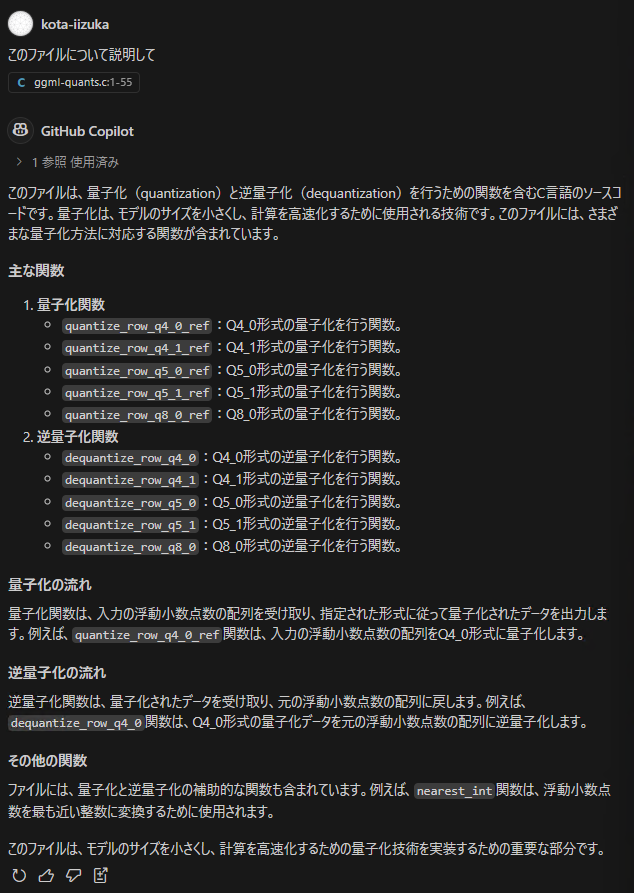
A list of several functions is provided as “Main functions,” but the specifically mentioned function names are concentrated in the first 400 lines or so, and there is no explanation at all about the quantization (a technique for model lightweighting) algorithm using the importance matrix in the latter part. Upon closer inspection, the number of referenced lines is displayed, indicating that it cannot include the entire file in the context.
Next, let’s ask o3-mini the same question. Since the length limit is exceeded and the full text cannot be given in chat, the file itself is indicated in the question, and search is turned on.

Details such as packing two 4-bit values are mentioned, which is slightly more detailed than GitHub Copilot, but similarly, quantization of less than 4 bits is not explained.
Let’s check Gemma 3’s output in comparison to these.

As you can see at first glance, the answer is in English even though the question was asked in Japanese. Although improved multilingual performance is claimed, it seems that English is still fundamentally used as the standard language.
However, if you add “in Japanese,” it will respond correctly in Japanese, so the language ability itself is not an issue, and it is thought that an appropriate system prompt needs to be set, similar to other LLMs.

The amount of description is larger than GitHub Copilot or o3-mini, and the detailed explanation of conceptual quantization and speed-up techniques is also impressive. However, looking closely, you can find incorrect parts, such as the explanation of quantization using the importance matrix and the application status of loop unrolling. Like other models, it needs to be handled carefully, being mindful of hallucinations.
Also, upon closer inspection, it’s not an explanation of the entire file, but only the last function, ggml_validate_row_data(), is explained. Checking the logs reveals that due to preprocessing on the Continue side, only about the last 250 lines of the file were included in the prompt, suggesting that application-side or model-side setting changes are necessary to input or interpret long texts.
Document Creation
Next, let’s request document creation. As a target, we will first use the quantize_q8_1 function from https://github.com/ggml-org/llama.cpp/blob/f08f4b3187b691bb08a8884ed39ebaa94e956707/ggml/src/ggml-cuda/quantize.cu#L4.
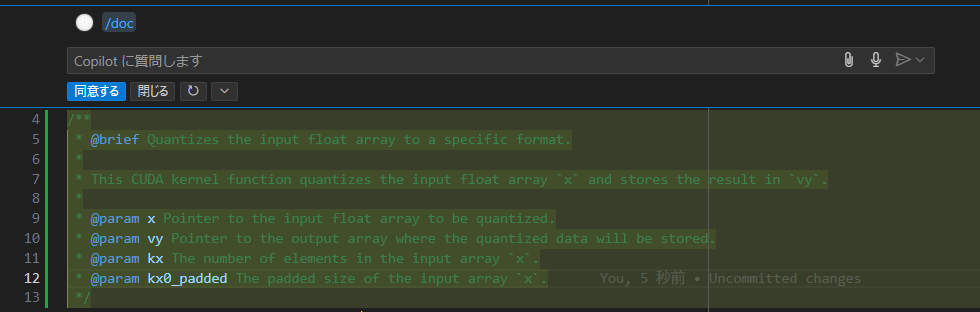
Select the line where the function is defined, right-click, and select Continue → Write a Docstring for this Code. The result was as follows:
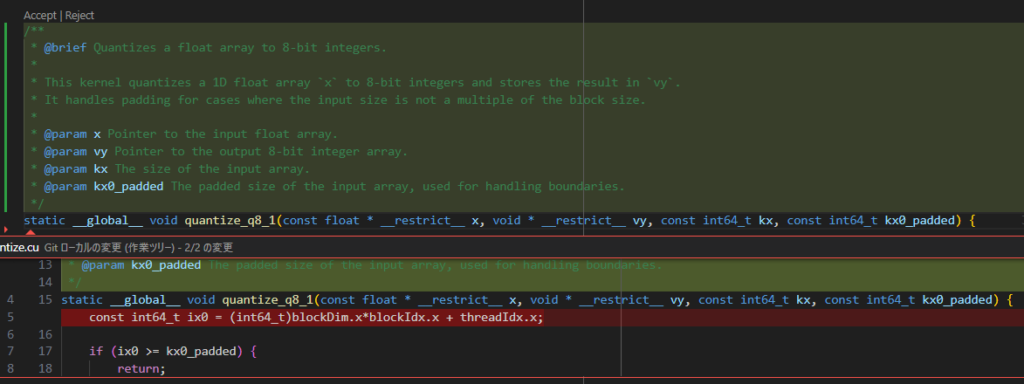
There is not much awkwardness in the document format or the added content. The output was slightly misaligned with Continue’s post-processing, and one line immediately after the function definition was deleted, but it’s easy to revert, so it doesn’t seem to be a major problem.
The content generated by GitHub Copilot was almost equivalent, and it seems that it can function as an alternative for this level of use.
Web Application Construction
Next, let’s look at application construction using Cline. As an example, let’s consider a web application that can list the GPU utilization status of servers and try to create a frontend with Vue.
First, initialize Vue and launch the workspace.
$ vue create llm-manager
$ cd llm-manager
$ code .
$ npm run serveAdd a simple .clinerules file like the following:
# .clinerules
This is a markdown file defining how the AI coding agent Cline should behave in this project.
It is expected to be read and improved by Cline.
## Role sharing with the user
Always ask the user for instructions in the following situations. Conversations with the user should be in Japanese.
- When the same process has been given and failed twice or more.
- When instructions are judged to be unclear.
- When writing code that is unsafe, or complex and difficult.
Other routine processes are expected to be performed automatically. Thoughts during automatic processing should be recorded in English.
## About Cline's memory
Use the `.cline/memory/` directory as external memory for Cline to work.
Context not saved here will be deleted, so be sure to save the results of the current work to this external memory before completing the work.
If this directory does not exist, it means Cline is being used for the first time, so create it.
The following information is categorized and saved in this directory:
- `summary.md`: Overall goal of this project
- `architecture.md`: Overall description of each directory/module
- `environment.md`: Procedure for creating the development environment
- `progress.md`: Work progress so far (list of which tasks are completed and which have not been started) / known issues
Also, save specifications and documents for APIs, tests, deployment, etc., in this memory as needed.
## Workflow Diagram
```mermaid
graph TD
A[Start] --> B{Check Memory}
B -->|Does not exist| C[Create New]
B -->|Exists| D[Check Contents]
D --> E[Execute Task]
E --> F{Update Needed?}
F -->|Yes| G[Update Memory]
F -->|No| H[End]
C --> D
G --> H
H --> A
```
This diagram shows the following flow:
1. Always check memory at the start of work.
2. If memory does not exist, create new.
3. If memory exists, check contents.
4. After task execution, if an update is needed, update memory.
5. After work ends, check memory again at the start of the next task.
Memory storage location: .cline/memory/ directoryFirst, focusing on some features, I entered, “Implement a UI in src/App.vue to list the GPU utilization of each server.” The result was as follows:
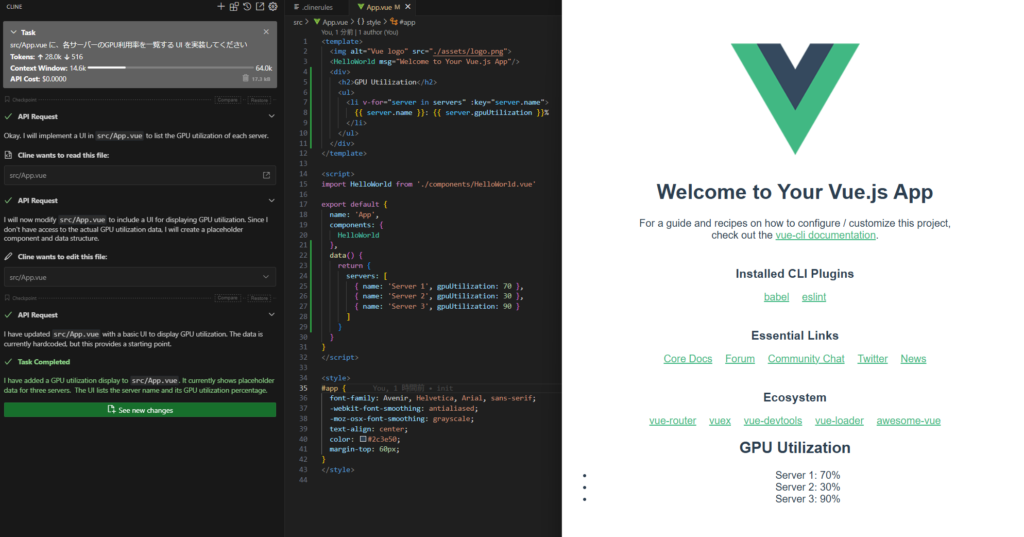
First, it can be confirmed that it supports Cline’s functions such as `read` and `edit`, and has reached a state of task completion. With Qwen2.5-Coder, there were many meaningless repetitions, making it unusable, so it has improved significantly in that respect.
However, there is still room for improvement in terms of functionality. In this screen, the default Vue.js screen has not disappeared, and it is unnatural that the GPU usage rate is displayed only with text. After interacting with it for several tens of minutes to get it corrected, without directly modifying the code body, this implementation was finally obtained.
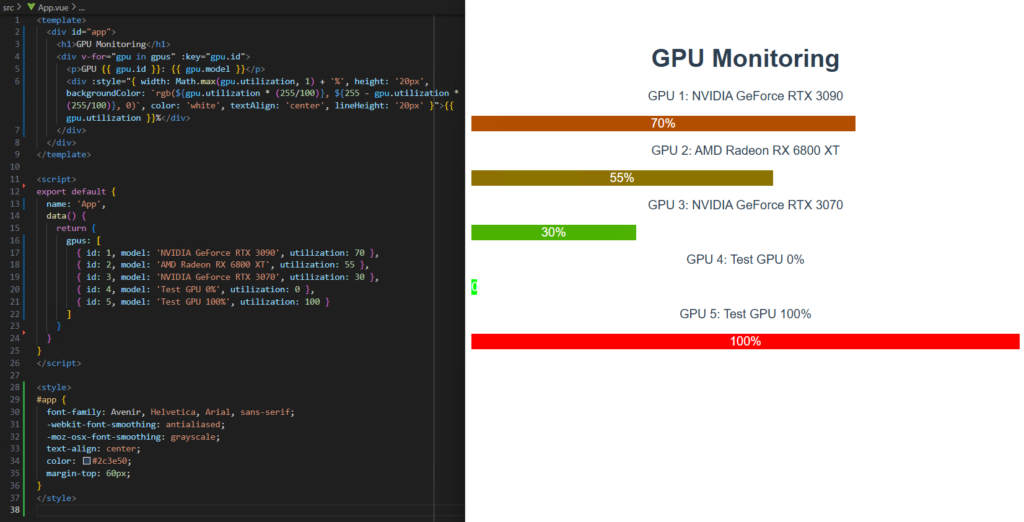
The impression is that the degree of adherence to prompts and expressive power are still several steps inferior to claude-3.7-sonnet or deepseek-r1, and it seemed to be particularly poor at rewriting large areas. On the other hand, tasks such as appropriately segmented function-level or line-level corrections are quite possible even with the current configuration, and a coding style where the overall design is done manually and the details are left to the agent also seems quite feasible.
Operational Check of a New Library
Recently, our company released a Multi-View Stereo library: https://github.com/fixstars/cuda-multi-view-stereo. When performing an operational check on such newly released libraries, errors often occur, and completing the operational check in such cases can be a painstaking task. This time, let’s try asking Cline to do this operational check.
For now, I vaguely threw at it, “Perform an operational check,” and it encountered a build error with cmake . and asked where CUDA was located.
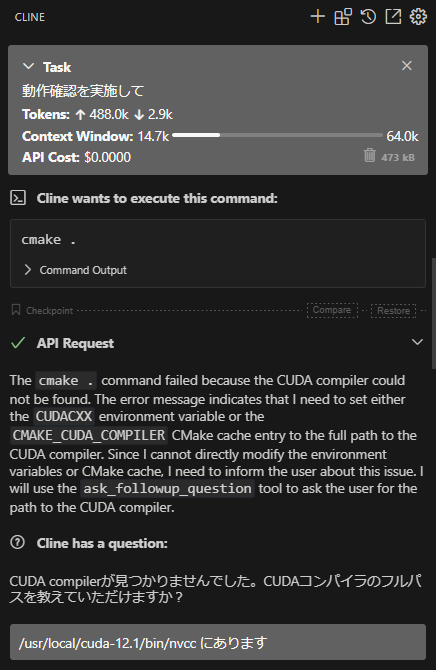
When I specified the path, it tried several compile options and then started working correctly, but then it stopped at the OpenCV installation.
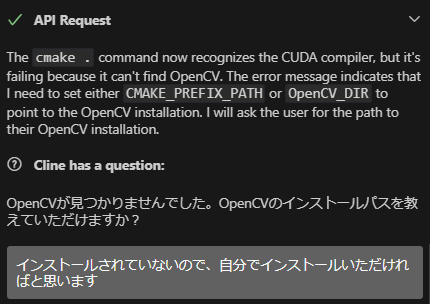
I asked it to do it itself, but it was trying the procedure to install with apt, and opencv-contrib was not included.
Let’s try throwing another task to build OpenCV from source. The installation procedure is on https://docs.opencv.org/4.x/d7/d9f/tutorial_linux_install.html, so I request it to read this and do it on its own.
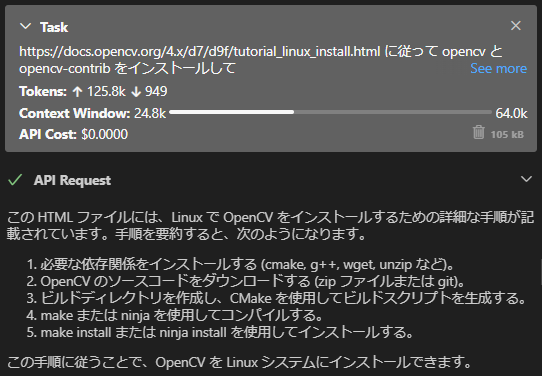
Then, it handled everything from downloading the documentation and source code to building.
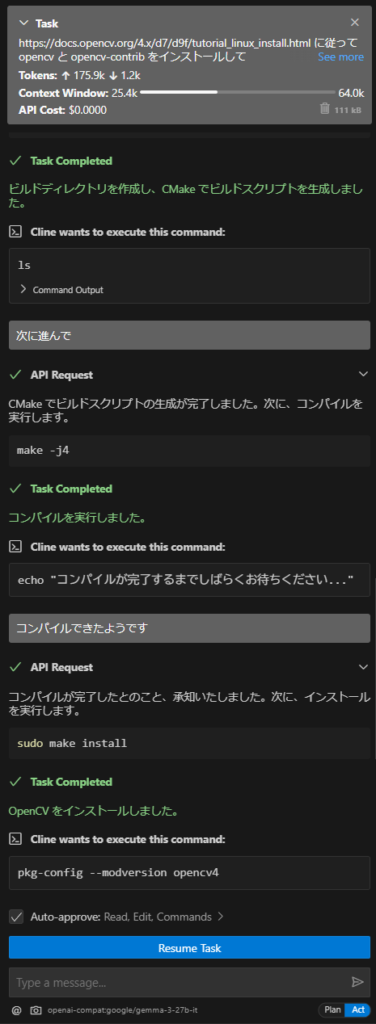
However, when I tried to ask it to build CUMVS again after the OpenCV build was complete, it repeated the same errors and meaningless modifications to CMakeLists.txt as before, and reached the request repetition limit.
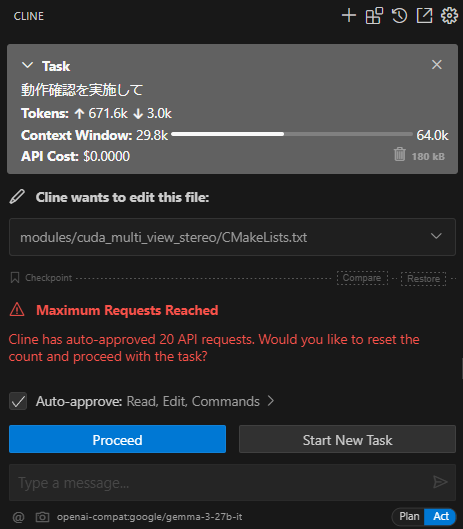
It might improve if I continued further, but in any case, Gemma 3’s performance still seems insufficient for tasks such as understanding complex contexts and debugging.
Also, since commands like apt install can change the environment, it is important to prepare an isolated environment so that you can revert and retry before executing commands.
Summary
In this article, we focused on the notable new model, Google DeepMind’s “Gemma 3 (27B),” built a local environment using ollama and vLLM, and conducted performance verification on four tasks assuming actual business operations. The main results of the verification are as follows:
- Code Summary Understanding:
- ✅ Outputs more detailed answers than GitHub Copilot or o3-mini.
- ⚠️ However, there are challenges in understanding entire large codes (context window limitations, misinterpretation of details, etc.).
- Document Creation:
- ✅ Confirmed usefulness at a level equivalent to Copilot for function-level document generation.
- ⚠️ Minor corrections are necessary during automatic generation, but it can sufficiently contribute to improving work efficiency.
- Web Application Construction (using Cline VSCode extension):
- ✅ Autonomous task execution is possible, and it is practical for small-scale code corrections and implementation support.
- ⚠️ On the other hand, it is still difficult to handle large-scale rewriting or complex design modifications, and continuous human intervention is essential.
- New Library Operational Check (for debugging purposes):
- ⚠️ Currently, autonomy for complex environment setup and error correction is insufficient.
- ⚠️ Human assistance is still necessary for resolving library dependencies and complex compilation errors.
Looking at the results of these four tasks, functions close to those of state-of-the-art closed models have been realized in some simple tasks. In terms of simple cost-effectiveness, it does not have an advantage over officially provided APIs, but in situations where security is important or APIs cannot be used, it is very effective for modern software development, and its adoption is expected to progress.
[Ad] Optimize your AI model performance with our Performance Engineering Platform – Fixstars AIBooster.
Fixstars AIBooster for GPU servers gathers runtime data, identifies bottlenecks, and enhances performance with actionable insights.
Learn more: Fixstars AIBooster Product Page