
* This blog post is an English translation of an article originally published in Japanese on December 6, 2023.
Introduction
Hello, this is Takagi, an engineer.
I am currently involved in an internal open-source project related to autonomous driving called adaskit, and as part of the project’s achievements, we have previously released libSGM and cuda-bundle-adjustment, among others.
This time, I will introduce our efforts to accelerate local feature computation, which is performed in Visual SLAM and SfM (Structure from Motion), using CUDA. Additionally, we have released the source code on GitHub under the name cuda-efficient-features.
fixstars/cuda-efficient-features
Background
Local Feature Computation
In Visual SLAM and SfM, relative pose estimation, the process of estimating the relative camera pose between two viewpoints, is often performed. In this process, it is common to collect pairs of corresponding feature points from the two viewpoints and estimate the camera pose based on geometric conditions (such as epipolar constraints) that hold between these corresponding points. Even for the same 3D point, its appearance in an image changes depending on the viewpoint’s position and orientation. Therefore, to correctly find corresponding points, it is necessary to perform (1) keypoint detection suitable for matching, and (2) feature extraction*, which converts the intensity patterns around keypoints into an appropriate representation. Here, we will refer to (1) and (2) collectively as local feature computation.
*Features are also called descriptors, and this process is sometimes referred to as descriptor extraction.
The Emergence of BAD and HashSIFT
Various methods for local feature computation have been proposed so far. SIFT, a representative method, is designed to be robust against scale changes and rotation of the viewpoint, and it still seems to be considered a baseline in terms of accuracy. Many methods have also been devised with computational efficiency in mind. Binary features, represented by methods like AKAZE and ORB, describe feature vectors as bit strings, offering the advantages of being memory-efficient and enabling fast similarity calculations.
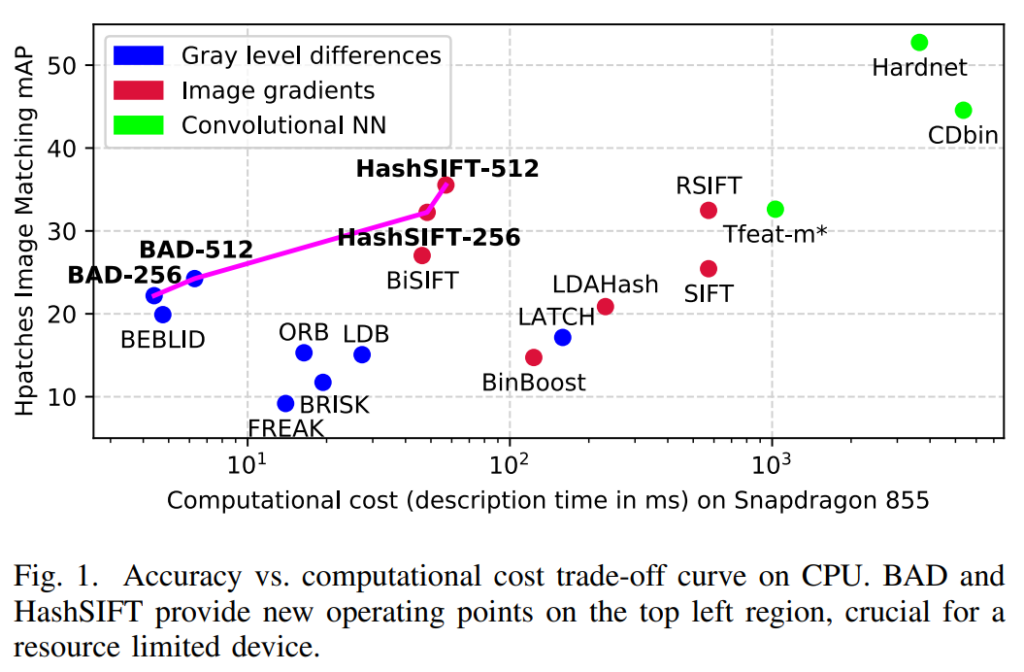
Recently, Suárez et al. proposed two binary features: BAD (Box Average Difference) and HashSIFT [1]. The red, blue, and green color coding in the figure below indicates categories of feature extraction methods. BAD, similar to ORB, is a method that encodes the differences in intensity values sampled from the vicinity of keypoints into a bit string. HashSIFT, like SIFT, utilizes intensity gradients; it binarizes SIFT features by applying a linear transformation and binarization after calculating them. Each point in the figure below plots the accuracy and computational cost of various local features, and as indicated by the pink line, BAD and HashSIFT show an excellent trade-off. The source code has been released by the authors and can be used via the OpenCV API.
Acceleration with CUDA Implementation
The motivation to accelerate local feature computation as much as possible arose from the real-time requirements of SLAM and the need to process large numbers of images in SfM. Since keypoint detection can be computed in parallel for each pixel, and feature extraction can be computed in parallel for each keypoint, acceleration using a GPU can be expected. This time, we decided to further accelerate the aforementioned BAD and HashSIFT with a CUDA implementation. Furthermore, although BAD and HashSIFT themselves do not include keypoint detection, in practice, keypoint detection and feature extraction are often performed as a set, so we decided to implement keypoint detection in CUDA as well.
Implementation of Feature Point Detection
Implementation Overview
Keypoint detection is based on the multi-scale FAST keypoint detection used in OpenCV’s ORB. We felt there were issues with the distribution of feature points in the OpenCV implementation, so we added some functional enhancements.
The figure below compares the OpenCV implementation (left) and our project’s implementation (right) when the maximum number of detected keypoints is set to 20,000.
In the OpenCV implementation, about 20,000 keypoints are detected, but most of them are concentrated in areas with strong cornerness (≒ contrast), such as tree leaves. Such a biased distribution of keypoints can lead to unstable camera pose estimation. To prevent keypoint bias, Non-Maximum Suppression (NMS), a process that prevents keypoints from being too close to each other (within a certain distance), is sometimes performed. Although OpenCV also has NMS implemented, its application range is extremely narrow (adjacent 8 pixels), and it cannot be adjusted, so it doesn’t function very well.
In this project, we enhanced the functionality to allow NMS to be performed with a specified radius (minimum allowable distance between keypoints). In the version with an NMS radius of 15 shown in the figure on the right, it can be seen that keypoints are detected evenly, including on buildings.


Processing Time
The keypoint detection algorithm is the same except for NMS, but we performed the following two main optimizations:
- Reusing device buffers to avoid memory reallocation/deallocation.
- Removing FAST-based corner score calculation due to changes in the NMS algorithm.
Since FAST keypoint detection originally has a short processing time, the processing time for CUDA API calls, such as device memory allocation and deallocation, becomes relatively non-negligible. In this project, assuming that keypoint detection will be called repeatedly, we minimize CUDA API calls by reusing device buffers once they are allocated.
Below is a comparison of processing time with OpenCV’s cv::cuda::ORB::detect, which is the basis of our implementation. We didn’t anticipate the extent of the acceleration effect, but it became apparent that it becomes more significant as the image size increases.
Measurement Environment
| GPU | RTX 3060 Ti |
| Input Images | 11 images from SceauxCastle |
| Number of KPs | Max 10,000 points |
| Image Size | Resized to FHD(1920×1080), 4K(3840×2160), 8K(7680×4320) for measurement |
| Measurement Method | Average processing time of 100 runs for each image, then average of 11 images |
Keypoint Detection Processing Time Comparison (Unit: [millisecond])
| Implementation \ Image Size | FHD | 4K | 8K |
| OpenCV | 2.5 | 5.4 | 17.5 |
| cuda-efficient-features | 1.6 | 2.9 | 5.5 |
Implementation of Feature Extraction
Implementation Overview
After refactoring the authors’ implementations of BAD and HashSIFT, we implemented them in CUDA and performed optimizations. For both BAD and HashSIFT, we applied optimizations such as optimal thread allocation, parallel reduction using Warp Shuffle, and reduction of CUDA API calls. We plan to introduce the details of HashSIFT acceleration in a separate article later.
Processing Time
Below is a comparison of processing time between the reference CPU implementation and the CUDA implementation. On the GPU, feature extraction for 10,000 keypoints can be performed in about 1 [msec]. Compared to multi-threaded CPU execution, we achieved a speedup of about 9-10 times for BAD and about 200-300 times for HashSIFT.
Measurement Environment
| Key | Value |
| CPU | Core i9-10900(2.80GHz) 10Core/20T |
| GPU | RTX 3060 Ti |
| Input Images | 11 images from SceauxCastle |
| Number of KPs | Fixed at 10,000 points |
| Measurement Method | Average processing time of 100 runs for each image, then average of 11 images |
Feature Extraction Processing Time Comparison (Unit: [millisecond])
| Implementation \ Descriptor | BAD256 | BAD512 | HashSIFT256 | HashSIFT512 |
| Reference CPU Single Thread | 28.6 | 52.3 | 604.9 | 740.1 |
| Reference CPU Multi Thread | 5.9 | 9.9 | 174.6 | 315.6 |
| cuda-efficient-features | 0.66 | 1.01 | 0.89 | 0.99 |
Conclusion
We have introduced the acceleration of local feature computation. As mentioned at the beginning, we have released the source code for this project on GitHub under the name cuda-efficient-features. If you want to accelerate SfM or SLAM, please try using it.
fixstars/cuda-efficient-features
In the future, we are also considering accelerating SfM as a whole by leveraging the results of this project.
Finally, we would like to express our sincere gratitude to our part-time assistants, Yuta Fujimoto and Daisuke Horii, for their significant contributions to this acceleration effort.
References
[1] Iago Suárez, José M. Buenaposada, and Luis Baumela. Revisiting binary local image description for resource limited devices. IEEE Robotics and Automation Letters, 6(4):8317–8324, 2021.