
At the Embedded Vision Summit, one of the standout panel discussions on Day 1 was “Edge AI and Vision in Robotics: From Benchmarks to Fleet-Scale Reality.” Moderated by Jeff Bier, the panel brought together a diverse group of experts, including representatives from robotics companies tackling vastly different domains—Torc Robotics (autonomous trucking), Agility Robotics (humanoid warehouse robots), and Simbe Robotics (retail inventory automation)—alongside silicon innovators from Qualcomm and Ambarella.
The core theme of the discussion centered on a classic friction point in engineering: the massive gap between a software pipeline that runs well on a laboratory benchmark and one that can be deployed reliably across a massive fleet of robots in production. Real-world commercial viability in robotics isn’t just about algorithmic accuracy; it is dictated by how efficiently that software maps to the physical constraints of the deployment target.
The Grim Reality of Fleet-Scale Constraints: Power, Thermals, and Cost
In a research setting, running an intensive vision pipeline on a high-power server GPU is standard practice. However, as the panel highlighted, shifting to a fleet-scale deployment flips the engineering priorities completely. Each vertical presents a distinct set of constraints:
- Autonomous Trucking (Torc Robotics): While a class-8 truck has more physical space and power headroom than a smaller robot, the system handles immense sensory throughput (multiple high-res cameras, LiDAR, Radar). The priority here is ultra-low latency and absolute deterministic predictability. Processing must be completed within fixed millisecond windows to ensure safety at highway speeds.
- Humanoid Logistics Robots (Agility Robotics): Bipedal robots like Digit must manage a highly strict power and weight envelope. Every watt consumed by an onboard processor directly reduces the robot’s battery life and operating time in a warehouse. Furthermore, passive or limited thermal dissipation means that running unoptimized code can cause hardware throttling, directly threatening the robot’s physical stability and balance loops.
- Retail Automation (Simbe Robotics): For inventory robots navigating grocery store aisles, the constraints are highly driven by unit cost and continuous operations. To make a fleet commercially viable for retail clients, the cost of the onboard compute stack must be kept low, forcing engineers to squeeze advanced vision pipelines into highly cost-efficient, lower-tier edge SoCs.
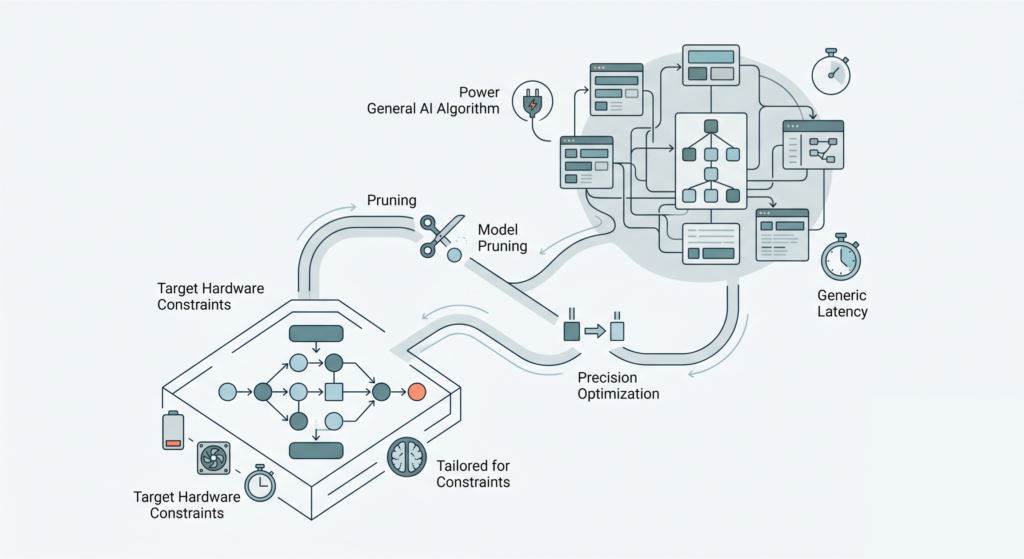
The Fixstars Perspective
This is where standard benchmarking fails to tell the full story. An image processing algorithm might hit impressive accuracy metrics on a standard dataset, but if it drains the battery or overloads the processor in production, it cannot be deployed.
To bridge this gap, software must undergo rigorous optimization—such as algorithmic pruning, precision optimization (e.g., converting FP32 code to INT8/INT4 fixed-point operations), and memory layout restructuring. At Fixstars, we specialize in these techniques to ensure that complex robotics perception pipelines execute efficiently within the exact power, thermal, and latency budgets required by the fleet.
Navigating Heterogeneous Silicon: The Mapping Challenge
The inclusion of chipmakers like Qualcomm and Ambarella on the panel underscored another major milestone in embedded systems: the rise of specialized, heterogeneous silicon. Modern system-on-chips (SoCs) are no longer just standard CPUs and GPUs; they feature highly specialized accelerators, including dedicated vector processors, Digital Signal Processors (DSPs), and specialized image signal processing (ISP) pipelines.
The panel discussed how leveraging these hardware blocks is essential for handling low-latency vision tasks on the edge. However, exploiting this specialized hardware creates a massive engineering overhead for software teams:
- Hardware Utilization Architecture: Standard software frameworks do not automatically map workloads efficiently across a mixed accelerator/GPU/CPU architecture. If a vision pipeline bottlenecks on the CPU while the dedicated processors sit idle, the hardware investment is wasted.
- Portability Friction: Different silicon providers offer entirely different software development kits (SDKs) and compilation tools. Optimizing a bipedal robot’s software stack for one chip architecture often means starting from scratch if the hardware platform changes next generation.
The Fixstars Perspective
Maximizing hardware utilization requires deep, low-level performance engineering. It involves analyzing execution graphs, identifying memory transfer bottlenecks between the system RAM and accelerator caches, and writing custom kernels tailored to the target silicon’s instruction set.
Fixstars has spent years optimization-mapping intensive computing workloads to diverse hardware architectures, including automotive and robotics platforms like the Renesas R-Car SoC series, custom FPGAs, and embedded GPUs. Our role is to handle the low-level complexities of code porting and validation so that robotics companies can focus on behavior and application logic, confident that their vision stack is pushing the hardware to its absolute limit safely and predictably.
Conclusion
Moving embedded processing from a controlled benchmark to a fleet-scale reality is the defining milestone for this generation of robotics. Commercial scaling requires a shift in mindset: software performance is no longer an afterthought to be handled after the algorithm is designed; it is a core architectural requirement.
Whether navigating a 40-ton autonomous truck or stabilizing a humanoid robot in a crowded fulfillment center, a driving or balancing algorithm is only as safe as its execution speed. By focusing heavily on embedded optimization and performance engineering, we help our partners transform advanced robotic vision into scalable, cost-effective, and commercially viable production realities.