
The dominant paradigm in production LLM deployment is straightforward: pick a model, optimize its serving stack, and scale horizontally. It works until it doesn’t. The moment your workload spans heterogeneous task types (code generation, long-context reasoning, structured extraction, multilingual dialogue), no single model sits at the Pareto frontier across all dimensions simultaneously. You’re always trading accuracy for latency, or cost for capability.
Picture a scatterplot with cost-per-token on the x-axis and task accuracy on the y-axis. Each model is a point. GPT-4-class models cluster in the upper-right: high accuracy, high cost. Open-weight 7B models sit in the lower-left: cheap, but limited. The Pareto frontier, the curve connecting the points where no model is strictly better on both axes, represents the best you can do with any single model. Constellation inference doesn’t pick a point on that curve. It constructs a new point above it, by combining the outputs of models scattered across the entire plot. The fused result inherits accuracy from the upper-right and cost structure from the lower-left, landing in a region no individual model can reach alone.
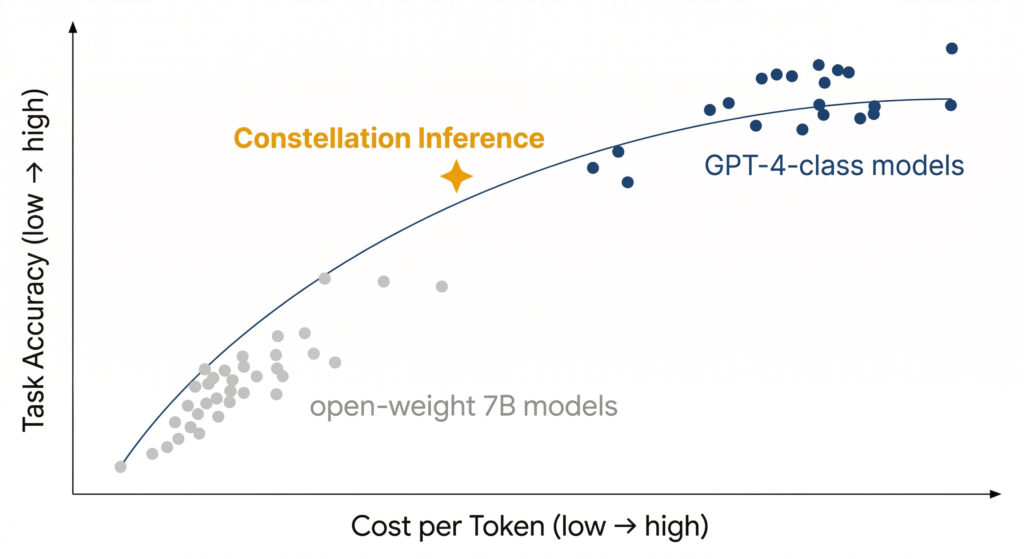
Constellation inference orchestration inverts the single-model constraint. Instead of asking which model is best, it asks which subset of models, queried concurrently, yields the optimal response for this specific input at this specific cost envelope. Running tens of models in parallel and fusing their outputs isn’t brute force. It’s a fundamentally different optimization surface.
This post breaks down the architecture, the routing mathematics, the fusion strategies, and the counterintuitive cost dynamics that make constellation inference not just viable but economically superior to monolithic deployment at scale.
The Architecture: Workload–Router–Pool at Constellation Scale
The foundation draws from the Workload–Router–Pool (WRP) paradigm, but extends it into a high-fan-out topology. In a traditional WRP system, a router dispatches each request to a single model instance selected from a pool. Constellation orchestration replaces the one-to-one dispatch with a one-to-many broadcast, where the router fans out a single query to N models simultaneously, and a downstream fusion layer aggregates the results [1].
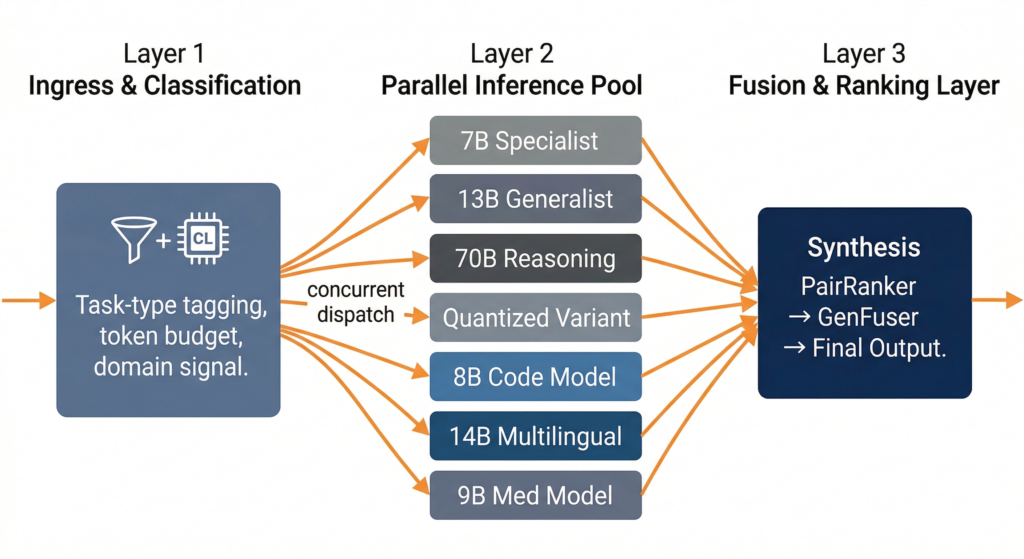
The three-layer stack looks like this:
Ingress & Classification Layer. Before any model sees the query, a lightweight classifier (typically a fine-tuned encoder model running at sub-millisecond latency) tags the input with task-type metadata: reasoning depth, domain signal, expected output structure, and token budget. This metadata drives the routing policy.
Parallel Inference Layer. The classified query is dispatched to a dynamically selected subset of the full model pool. Not every query hits every model. The routing policy selects a constellation, a task-specific subset, based on the classifier output and current infrastructure state (GPU utilization, queue depth, cache residency). Models execute concurrently, with inference calls parallelized across distributed GPU partitions managed by a hardware resource orchestrator handling memory movement and compute virtualization.
Fusion & Ranking Layer. Raw outputs from the constellation are aggregated through a learned fusion mechanism. This is where approaches like PairRanker (pairwise comparison of candidate outputs) and GenFuser (generative fusion of top-ranked candidates) come into play. The fusion layer doesn’t just pick the best response. It synthesizes a response that inherits the strongest signal from each contributing model [2].
Routing: From Static Dispatch to Learned Per-Query Optimization
The routing layer is the intellectual core of constellation inference. Naive approaches (round-robin, static weighting, or random allocation) leave enormous performance on the table. The research is converging on three classes of routing strategies, each with distinct trade-off profiles.
Predictive classification routing treats each model as a domain-specific expert. Systems like PolyRouter build predictive classifiers that learn to route based on query semantics, mapping input embeddings to predicted per-model quality scores. The router then selects the top-k models whose predicted scores exceed a dynamic threshold. This is fast (routing overhead is a single forward pass through a small classifier) and adapts well to workload drift.
Graph-based routing models the relationships between tasks, queries, and LLMs as a heterogeneous graph. GraphRouter performs inductive edge prediction using graph neural networks, which enables it to generalize to unseen query types and newly added models without retraining the router itself. For constellation systems where the model pool changes frequently (new model releases, quantization variants, fine-tuned specialists), this is a significant operational advantage [4].
Hierarchical cascading with parallel fallback. Rather than committing to a fixed constellation upfront, cascading routers first dispatch to a small, cheap model subset. If confidence scores from the fusion layer fall below a threshold, additional models are activated in a second wave. This hybrid approach bounds worst-case latency while preserving the accuracy ceiling of full-constellation inference.
The empirical results from multi-objective routing optimization are striking: research on Pick and Spin-style orchestration has demonstrated a 21.7% accuracy improvement, 33% mean latency reduction, and 25% cost reduction compared to random allocation baselines [1].
The Fusion Problem: From Ensemble Voting to Generative Synthesis
Running a dozen or more models in parallel is only half the problem. The harder question is: how do you combine that many different outputs into one response that’s better than any individual?
Classical ensemble methods like majority voting and weighted averaging work for classification but break down for open-ended generation. The constellation approach requires generative fusion: a mechanism that understands the semantic content of each candidate and synthesizes a composite output.
The LM-Blender framework offers a useful reference architecture. Its two-stage pipeline (PairRanker for pairwise comparison followed by GenFuser for output synthesis) achieves quality improvements that exceed what any single model in the ensemble can produce independently. The key insight is that different models fail in different, largely uncorrelated ways. Model A might hallucinate a date while getting the reasoning chain correct; Model B might nail the factual grounding but produce an incoherent structure. Fusion exploits this decorrelation.
For constellation systems operating at scale, with tens of models per query, the fusion layer itself becomes a performance-critical component. Practical implementations typically use a tiered approach: a fast ranker (often a cross-encoder) eliminates the bottom 60–70% of candidates, and the generative fuser operates only on the top-ranked subset. This keeps fusion latency bounded even as the constellation size grows.
The Cost Paradox: Why Many Models Can Be Cheaper Than One
The most common objection to constellation inference is cost. Running dozens of models simultaneously sounds like it should cost an order of magnitude more than running one. In practice, the economics work in the opposite direction, for several reasons [6].
Smaller models, collectively smarter. The model pool in a constellation system is heterogeneous by design. It includes 7B-parameter specialists alongside 70B generalists, quantized variants (GPTQ, AWQ, GGUF) alongside full-precision checkpoints, and fine-tuned domain models alongside general-purpose foundations. The per-token cost of running a 7B model is roughly 1/50th that of a 405B model. A constellation of mid-tier models averaging 13B parameters can deliver accuracy exceeding a single 405B model at a fraction of the aggregate compute cost.
Scale-to-zero and adaptive provisioning. Kubernetes-native orchestration frameworks enable scale-to-zero for models not currently in any active constellation. If the routing policy hasn’t dispatched to a particular specialist in the last N minutes, its GPU allocation is released. This is fundamentally more efficient than keeping a single large model perpetually warm. You only pay for the models that are actually contributing to active inference.
Speculative decoding across the constellation. Smaller models in the pool can serve as draft models for speculative decoding, generating 3–12 candidate tokens per step. When the draft model’s predictions align with the verifier, you get multiple tokens for roughly the cost of a single target-model step, yielding 2–3x speedups on generation-heavy workloads.
Reduced retry and fallback costs. Single-model deployments incur hidden costs from retries on low-quality outputs, fallback logic, and human review of hallucinated content. Constellation inference, by fusing across decorrelated error distributions, reduces the rate of catastrophic failures, which reduces downstream correction costs that rarely appear in naive TCO calculations.
Latency Engineering: Keeping P99 Bounded Across Concurrent Paths
Parallel execution introduces a well-known latency challenge: your end-to-end latency is bounded by the slowest model in the constellation, not the fastest. Left unmanaged, this tail-latency problem can make constellation inference impractical for real-time applications [3].
Three mechanisms keep P99 latency in check.
Staggered dispatch with early termination. Not all models in the constellation need to complete before fusion can begin. The fusion layer can operate incrementally, beginning synthesis as soon as a quorum of high-confidence responses arrives, and incorporating late-arriving responses only if they arrive within a time budget. This converts the latency distribution from max(all models) to percentile(top-k models).
Asynchronous decoupling of planning and execution. Drawing from recent advances in agent architectures, the inference planning step (which models to query, with what parameters) is decoupled from the actual execution. The router commits the dispatch plan while models are still spinning up, and results stream back asynchronously. This pipeline parallelism hides much of the scheduling overhead.
Prefix-aware cache routing. For models that share architectural families or tokenizer vocabularies, KV-cache state can be partially transferred between instances. Constellation-aware schedulers route requests to GPU partitions that already hold relevant cached prefixes, reducing time-to-first-token across the pool [7].
When Constellation Inference Makes Sense, and When It Doesn’t
Constellation orchestration isn’t universally optimal. But for the right deployment profile, it’s a decisive architectural advantage. Here’s where it delivers the highest ROI.
SaaS platforms serving multi-task endpoints. If your product exposes a single API that handles summarization, translation, code generation, and structured extraction, and you’re currently routing all of it through one general-purpose model, you’re paying frontier-model pricing for tasks that a 7B specialist handles better. Constellation orchestration lets you serve every task type from a single infrastructure layer while routing each query to the optimal model subset. The result is better per-task accuracy at lower aggregate cost.
High-stakes domains where hallucinations carry real liability. In medical informatics, legal document analysis, and financial compliance, a single model’s confident-but-wrong output can trigger regulatory exposure or patient harm. Constellation inference provides a form of model consensus: when multiple architecturally diverse models converge on the same answer, confidence is well-calibrated. When they diverge, the fusion layer can flag uncertainty rather than silently propagating a single model’s error. This “jury deliberation” pattern is becoming a de facto requirement for AI systems operating under regulatory scrutiny.
Organizations already running multi-model infrastructure. If you’re on Kubernetes with GPU partitioning, or using managed inference platforms that support multiple model endpoints, the marginal infrastructure cost of constellation orchestration is low. You’re adding a routing and fusion layer on top of capacity you already manage. The shift is primarily architectural, not infrastructural.
Where it’s overkill. Single-task deployments where one well-tuned model already meets your quality bar. Latency-critical applications where sub-100ms time-to-first-token is non-negotiable and the fusion overhead is unacceptable. Teams without the operational maturity to monitor and manage a multi-model serving stack. Constellation systems are powerful but not simple, and under-instrumented deployments will create more problems than they solve.
What’s Next: Self-Optimizing Constellations
The current generation of constellation systems relies on learned but largely static routing policies. The next frontier is self-optimizing constellations: systems where the routing policy, fusion weights, and even the model pool composition adapt continuously based on production traffic patterns [8].
Emerging work on inductive graph-based routing already hints at this future: routers that can incorporate new models without retraining, and that adjust selection probabilities based on observed per-model accuracy drift. Combined with reinforcement learning from production feedback signals, the constellation itself becomes a continuously improving system, not just a static ensemble [9].
For ML engineers building the next generation of inference infrastructure, the question is no longer which model to deploy. It’s which constellation to orchestrate.
References
- Y. Li, S. Zhang, et al., “Efficient Multi-Model Orchestration for Self-Hosted Large Language Models,” arXiv preprint arXiv:2512.22402, Dec. 2025. https://arxiv.org/abs/2512.22402
- A. Shnarch, et al., “Orchestration of Experts: The First-Principle Multi-Model System,” Hugging Face Blog (Leeroo), 2024. https://huggingface.co/blog/alirezamsh/leeroo-multi-model-system
- “The Evolution of Tool Use in LLM Agents: From Single-Tool Call to Multi-Tool Orchestration,” arXiv preprint arXiv:2603.22862, Mar. 2026. https://arxiv.org/html/2603.22862
- “LLM Orchestration in 2026: Top Frameworks and Gateways,” AIMultiple, 2026. https://aimultiple.com/llm-orchestration
- “vLLM vs Triton vs TGI: Choosing the Right LLM Serving Framework,” Clarifai Blog, 2025. https://www.clarifai.com/blog/model-serving-framework/
- “Local LLM Inference in 2026: The Complete Guide to Tools, Hardware & Open-Weight Models,” Starmorph Blog, 2026. https://blog.starmorph.com/blog/local-llm-inference-tools-guide
- “Multiple Local LLMs 2026: Multi-Model Setup,” SitePoint, 2026. https://www.sitepoint.com/multiple-local-llms-setup-2026/
- “Top LLMs and AI Trends for 2026,” Clarifai Industry Guide, 2026. https://www.clarifai.com/blog/llms-and-ai-trends
- “LLM Orchestration: Frameworks + Best Practices,” Orq.ai Blog, 2025. https://orq.ai/blog/llm-orchestration