
* This blog post is an English translation of an article originally published in Japanese on August 21, 2023.
TL;DR
- What is AMX?
- Advanced Matrix Extension
- A new instruction set introduced by Intel with 4th Gen Xeon (Sapphire Rapids)
- Dedicated instructions for high-speed matrix multiplication
- Theoretical performance: 3,482 GFLOPS per core (16 times that of AVX512)
- Note: AVX512 theoretical performance: 217 GFLOPS per core
- Sample Code
- Benchmark with OpenBLAS
- Single core: 11.7 times faster than AVX512
- 112 cores: 2 times faster than AVX512
- Note: This is likely due to factors like operating frequency and optimization levels.
Introduction
With the explosive growth of AI, the demand for high-performance computing environments is on the rise. GPUs are widely used due to the nature of these computations, but similar calculations can also be performed on CPUs. While CPUs can be used in environments where GPUs cannot be used due to restrictions on power consumption, heat generation etc…, they are not specialized for matrix operations. High-speed calculations are possible using Intel/AMD’s AVX (Advanced Vector Extensions) and ARM’s SVE (Scalable Vector Extension), but matrix operations required a complex combination of multiple instructions.
To address this, Intel introduced a new instruction set, AMX (Advanced Matrix Extension), starting with the Xeon Sapphire Rapids (4th generation) in 2021. As the name suggests, it is an extension specialized for matrix operations and does not replace AVX. While AMX can only handle matrix multiplication, it uses very simple instructions and can perform calculations several to tens of times faster than matrix operations using AVX.
Together with our intern, Koga-san, we investigated everything from AMX instructions to their various operations. This article provides a detailed explanation of AMX registers, the instruction set, the behavior of each instruction, and sample code.
Target Audience
- Those with some understanding of AVX (Advanced VECTOR Extensions)
- Those who want to learn about AMX (Advanced MATRIX Extensions)
Basic AMX Terminology
- Tile
- A sub-matrix that can be referenced at once in AMX. There is a one-to-one correspondence between a tile and a TILEDATA register.
- Matrices are divided into “tiles,” and matrix multiplication is computed through multiply-accumulate operations between these tiles.
- TILEDATA Register
- A register that stores a tile. There are 8 such registers:
tmm0, tmm1, ..., tmm7. - A
tmm<N>register can store a maximum of 16 rows x 64 bytes (=1024 bytes) of data. - A TILEDATA register is in an invalid state if its number of rows or column size is set to 0 in the TILECFG register (explained below).
- A register that stores a tile. There are 8 such registers:
- TILECFG Register
- A single register that stores the configuration for the TILEDATA registers.
- By configuring this register, you can set the size of a TILEDATA register, for example, to 1 row x 64 bytes.
- Palette
- Corresponds to the operating mode of AMX.
- Specifying a “palette” determines the usable tile sizes and the type of operations (currently, only matrix multiplication is available).
AMX Calculation Flow
The execution flow of AMX is as follows (details of each instruction are described later):
- Tile Configuration
- The
ldtilecfginstruction configures the TILECFG register. The TILEDATA registers are also initialized at this time.
- The
- Tile Load
- The
tileloaddinstruction loads data from memory into a TILEDATA register.
- The
- TMUL Operation
- Instructions like
tdpbf16ps(BF16) perform operations between TILEDATA registers.
- Instructions like
- Tile Store
- The
tilestoredinstruction writes the result from a TILEDATA register back to memory.
- The
- Tile Release
- The
tilereleaseinstruction resets TILECFG to its initial state. The TILEDATA registers are also initialized.
- The

About the TILECFG Register
The TILECFG register has a data structure similar to the tileconfig_t struct shown below. A program can configure TILECFG by loading this structure.
struct tileconfig_t {
uint8_t palette_id;
uint8_t startRow;
uint8_t reserved[14];
uint16_t colb[16];
uint8_t rows[16];
};The members of tileconfig_t have the following meanings:
uint8_t pallete_id- The palette.
- 0: Default. AMX operations cannot be used.
- 1: Matrix multiplication. Provides 8 KB of internal storage, with each of the 8 TILEDATA registers holding up to 1 KB (16 rows x 64 bytes) of data.
- Others: Undefined. Setting to other values will cause an error.
- Values of 2 and higher may be defined in the future for changes that break compatibility.
uint8_t startRow- The restart position if an operation is interrupted by a page fault, etc.
- This is used internally, so you should specify 0 when setting it.
uint8_t reserved- Reserved area.
uint16_t colb[16]- The number of bytes per row for each TILEDATA register. Maximum is 64.
colb[0] corresponds to tmm0,etc.colb[8]and beyond are ignored.
uint8_t rows[16]- The number of rows for each TILEDATA register. Maximum is 16.
rows[0] corresponds to tmm0, etc.rows[8]and beyond are ignored.
AMX Instruction Set
The AMX instruction sets and their supported microarchitectures are defined as follows. As of this writing (August 2025), only architectures up to Granite Rapids D are actually available. Therefore, this article will detail the instruction sets listed in the Intel® Intrinsics Guide up to AMX-TILE, AMX-BF16, AMX-INT8, AMX-FP16, and AMX-COMPLEX.
Even if your CPU does not support them (including the Diamond Rapids instruction set), you can run them on the Intel Software Development Emulator.
✅: Supported, ❌: Not Supported.
| Instruction Set (AMX- omitted) | Sapphire Rapids | Granite Rapids | Granite Rapids D | Diamond Rapids | Instruction Set Overview |
| TILE | ✅ | ✅ | ✅ | ✅ | Basic instructions for tile loading, storing, config, etc. |
| BF16 | ✅ | ✅ | ✅ | ✅ | BF16 matrix multiplication |
| INT8 | ✅ | ✅ | ✅ | ✅ | INT8 matrix multiplication |
| FP16 | ❌ | ✅ | ✅ | ✅ | FP16 matrix multiplication |
| COMPLEX | ❌ | ❌ | ✅ | ✅ | FP16 complex matrix multiplication |
| MOVRS | ❌ | ❌ | ❌ | ✅ | Tile loading from read-shared memory locations, etc. |
| AVX512 | ❌ | ❌ | ❌ | ✅ | Moving data from TILEDATA to zmm registers, etc. |
| FP8 | ❌ | ❌ | ❌ | ✅ | FP8 matrix multiplication |
| TF32 | ❌ | ❌ | ❌ | ✅ | TF32 matrix multiplication |
| TRANSPOSE | ❌ | ❌ | ❌ | ✅ | Instructions including matrix transpose |
The available instructions for each instruction set (up to COMPLEX) are as follows.
The Instruction and Intrinsics are quoted from the Intel® Intrinsics Guide. Throughput and Latency are from the Intel® 64 and IA-32 Architectures Optimization Reference Manual. (– indicates that the information is not listed).
| Instruction Set | Instruction | Intrinsics | Throughput | Latency |
| TILE | ldtilecfg m512 | void _tile_loadconfig (const void * mem_addr) | – | 204 |
| TILE | sttilecfg m512 | void _tile_storeconfig (void * mem_addr) | – | 19 |
| TILE | tilerelease | void _tile_release () | – | 13 |
| TILE | tileloadd tmm, sibmem | void __tile_loadd (__tile1024i* dst, const void* base, size_t stride)void _tile_loadd (constexpr int dst, const void * base, size_t stride) | 8 | 45 |
| TILE | tileloaddt1 tmm, sibmem | void __tile_stream_loadd (__tile1024i* dst, const void* base, size_t stride)void _tile_stream_loadd (constexpr int dst, const void * base, size_t stride) | 33 | 48 |
| TILE | tilestored sibmem, tmm | void __tile_stored (void* base, size_t stride, __tile1024i src)void _tile_stored (constexpr int src, void * base, size_t stride) | 16 | – |
| TILE | tilezero tmm | void _tile_zero (constexpr int tdest)void _tile_zero (constexpr int tdest) | 0 | 16 |
| BF16 | tdpbf16ps tmm, tmm, tmm | void __tile_dpbf16ps (__tile1024i* dst, __tile1024i src0, __tile1024i src1)void _tile_dpbf16ps (constexpr int dst, constexpr int a, constexpr int b) | 16 | 52 |
| INT8 | tdpbssd tmm, tmm, tmm | void __tile_dpbssd (__tile1024i* dst, __tile1024i src0, __tile1024i src1)void _tile_dpbssd (constexpr int dst, constexpr int a, constexpr int b) | 16 | 52 |
| INT8 | tdpbsud tmm, tmm, tmm | void __tile_dpbsud (__tile1024i* dst, __tile1024i src0, __tile1024i src1)void _tile_dpbsud (constexpr int dst, constexpr int a, constexpr int b) | 16 | 52 |
| INT8 | tdpbusd tmm, tmm, tmm | void __tile_dpbusd (__tile1024i* dst, __tile1024i src0, __tile1024i src1)void _tile_dpbusd (constexpr int dst, constexpr int a, constexpr int b) | 16 | 52 |
| INT8 | tdpbuud tmm, tmm, tmm | void __tile_dpbuud (__tile1024i* dst, __tile1024i src0, __tile1024i src1)void _tile_dpbuud (constexpr int dst, constexpr int a, constexpr int b) | 16 | 52 |
| FP16 | tdpfp16ps tmm, tmm, tmm | void __tile_dpfp16ps (__tile1024i* dst, __tile1024i src0, __tile1024i src1)void _tile_dpfp16ps (constexpr int dst, constexpr int a, constexpr int b) | 16? | 52? |
| COMPLEX | tcmmrlfp16ps tmm, tmm, tmm | void __tile_cmmimfp16ps (__tile1024i* dst, __tile1024i src0, __tile1024i src1)void _tile_cmmrlfp16ps (constexpr int dst, constexpr int a, constexpr int b) | 16? | 52? |
| COMPLEX | tcmmimfp16ps tmm, tmm, tmm | void __tile_cmmrlfp16ps (__tile1024i* dst, __tile1024i src0, __tile1024i src1)void _tile_cmmimfp16ps (constexpr int dst, constexpr int a, constexpr int b) | 16? | 52? |
Tile Manipulation Instructions (AMX-TILE)
ldtilecfg
Reads 64 bytes from the specified memory location and loads it into TILECFG. The memory location must contain 64 bytes of data in the tileconfig_t format. This instruction has high latency, so it is recommended to reuse the same configuration as much as possible.
sttilecfg
Writes the 64-byte content of TILECFG to the specified memory location. If the ldtilecfg instruction has not been executed, 64 bytes of zeros will be written.
tilerelease
Resets the TILEDATA and TILECFG registers to their initial state. Specifically, it zero-fills both TILEDATA and TILECFG.
tileloadd / tileloaddt1
Loads data from the specified memory location into a TILEDATA register. The data address is specified using SIB addressing. In intrinsics, you can specify a base address void *base and a stride size_t stride. Specifically, it reads colb bytes from the memory location base + i * stride as the i-th row of the TILEDATA register. If TILECFG.colb is less than 64 or TILECFG.rows is less than 16, there will be an area in the TILEDATA register that is not loaded, and this area will be zero-filled. An exception is thrown if TILECFG is not configured (i.e., palette_id is 0).
An example of tileloadd is shown in the following diagram.
TILECFG.colb[0] is set to 63, and TILECFG.rows[0] is set to 15.- Only 15 rows of 63 bytes are valid in
tmm0.
- Only 15 rows of 63 bytes are valid in
- With
_tile_loadd(0, base, 128), data is loaded from a matrix whose starting address isbasewith astride of 128. - Data is loaded into
tmm0as follows:- Row 0: 63 bytes are loaded from
base + (0) * (128) = base+0. - Row 1: 63 bytes are loaded from
base + (1) * (128) = base+128. - This repeats up to row 15.
- Since TILEDATA is 64 bytes x 16 rows, the unloaded area is zero-filled.
- Row 0: 63 bytes are loaded from
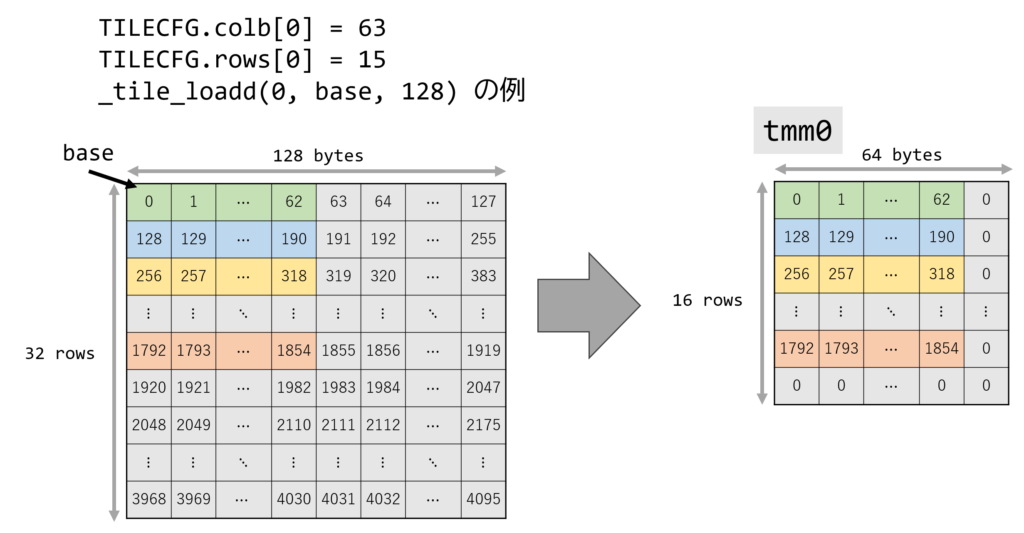
tileloaddt1 is the non-temporal version of tileloadd. It provides a hint that the data loaded by tileloaddt1 has low temporal locality and does not need to be kept in the cache.
tilestored
Writes the value of the specified TILEDATA register to the specified memory location. Similar to tileloadd, the data address is specified using SIB addressing.
tilezero
Zero-fills the specified TILEDATA register.
TMUL Instructions
BF16, INT8, FP16, and COMPLEX each have corresponding TMUL instructions. A TMUL instruction takes three TILEDATA registers, let’s call them X, Y, and Z, and performs a multiply-accumulate operation like Z += Matmul(X, Y) in the TMUL (Tile Matrix Multiply Unit).
TMUL instructions actually perform dot-product SIMD operations, so they read and write TILEDATA according to the following rules:
- Data is row-wise based.
- The unit of operation is 4 bytes (32-bit).
For example, an INT8 TMUL input groups four values and performs an operation that outputs an int32.
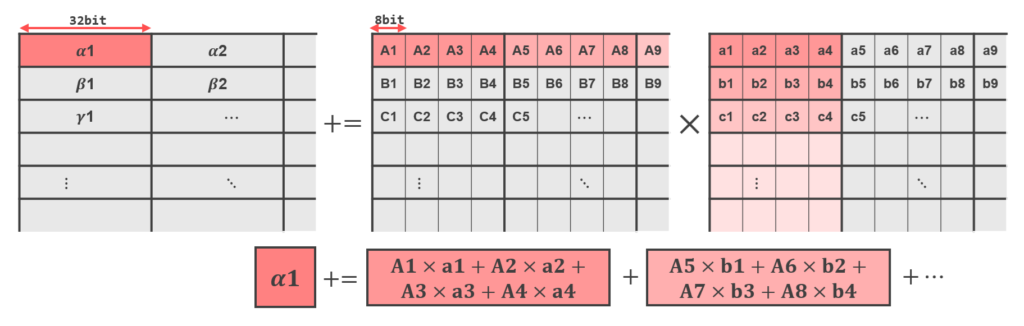
In a normal matrix multiplication, one of the source matrices was accessed column-wise. In AMX, all registers are accessed row-wise, so the layout of the matrix needs to be changed as shown below. It is important to note that this layout change is not a matrix transpose.
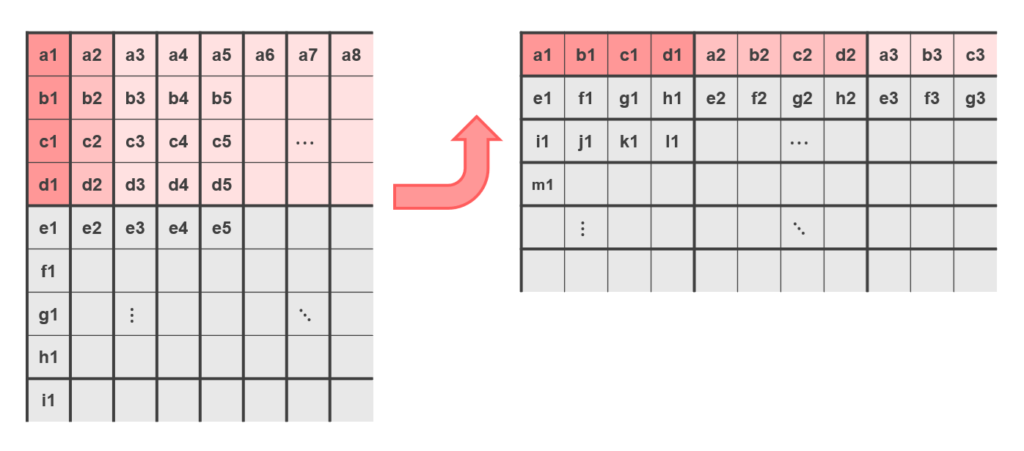
Therefore, to compute a normal matrix multiplication, you need to reorder the elements of the right-hand matrix. Note that if the length of the inner dimension is not a multiple of 4, it will result in an error, so you must pad with zeros.
For a BF16 TMUL, it operates on two 16-bit values at a time and outputs a float.
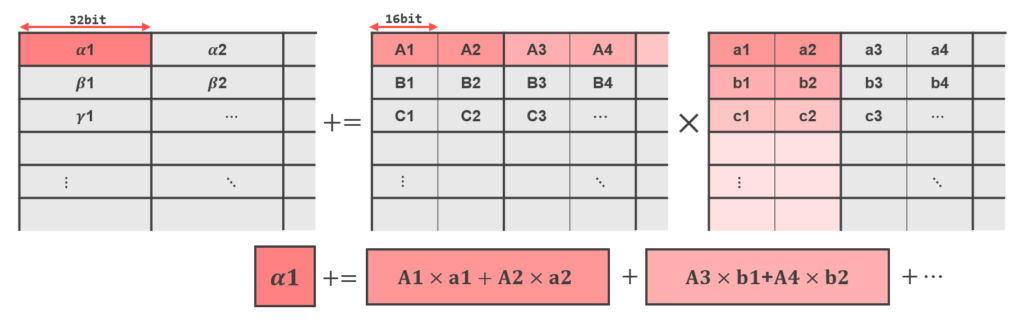
tdpbf16ps
Interprets the values in TILEDATA as BF16 (BrainFloat16) and outputs an FP32 matrix. Internally, BF16 values are pre-cast to FP32, and the computation is performed in FP32.
tdpbuud, tdpbsud, tdpbusd, tdpbssd
Interprets the values in TILEDATA as INT8 (int8_t or uint8_t) and outputs an INT32 matrix. The ** part of tdpb**d indicates signedness of the source TILEDATA registers.
uu=Uint8_t x Uint8_tsu=int8_t x Uint8_tus=Uint8_t x int8_tss=int8_t x int8_t
tdpfp16ps
Interprets the values in TILEDATA as FP16 and outputs an FP32 matrix. Internally, FP16 values are pre-cast to FP32, and the computation is performed in FP32.
tcmmrlfp16ps, tcmmimfp16ps
Interprets the values in TILEDATA as Complex16 (where both the real part real and imaginary part imm are FP16) and outputs an FP32 matrix. The input TILEDATA is interpreted as containing alternating real and imaginary parts: real0, imm0, real1, imm1, .... tcmmrlfp16ps outputs the real part, and tcmmimfp16ps outputs the imaginary part.
Comparison of AVX and AMX
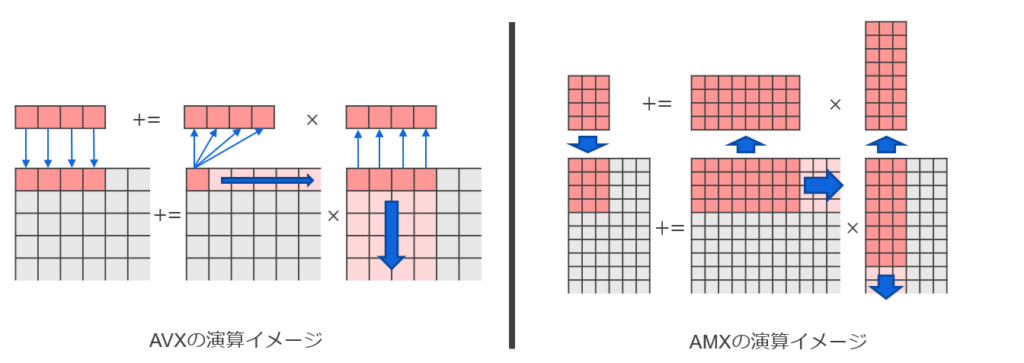
The diagram below shows the difference in matrix multiplication between AVX and AMX. You can see that while AVX operates on rows and columns incrementally, AMX can operate on sub-matrices all at once.
Theoretical Performance
Let’s compare the theoretical performance of AVX and AMX. We’ll assume a Xeon Platinum 8480 (Sapphire Rapids) CPU operating at 3.4 GHz.
For AVX, we consider the most efficient _mm512_fmadd_ph (vfmadd***ph).
vfmadd***phcan process 512 bits, is an FMA (one addition and one multiplication), and has a throughput of 0.5 inst/cycle, so: (512/16) × 2 × 0.5 = 32 FLO/instruction.- A 3.4 GHz CPU can process 3.4 G instructions, so: 3.4 × 10⁹ instructions/(Core*s).
- It has 56 physical cores: 56 Core.
- Each physical core has 2 ports: 2 ports.
- Multiplying these together gives 11.9 TFLOPS.
For AMX, we consider tdpbf16ps which processes BF16.
- At the maximum tile size, the calculation is (32×2) × ((64×16)/4) / 16 = 1024 FLO/instruction.
- It performs 32 FMA operations for each element of the destination TILEDATA and adds to itself, so 32 × 2 FLO/elem.
- The destination TILEDATA becomes FP32, so (64×16)/4 elem.
- The throughput of
tdpbf16psis 16 (cycles).
- A 3.4 GHz CPU can process 3.4 G instructions, so: 3.4 × 10⁹ instructions/(Core*s).
- It has 56 physical cores: 56 Core.
- Multiplying these together gives 195 TFLOPS.
Thus, in terms of ideal, raw computational power, AMX can achieve about 16 times the FLOPS of AVX. However, in practice, AVX requires frequent register swaps, while AMX requires tile configuration. Depending on the use case, AMX might deliver over 10 times the performance, or it might be limited to around 2 times. When applying AMX, it is necessary to analyze the characteristics of the use case, identify bottlenecks, and perform appropriate tuning.
Sample Code
Here is a simple sample code for AMX. The sample code in this article assumes compilation with clang++. This is because clang++ supports intrinsics using the __tile1024i struct, which can hide the TILECFG manipulation. For g++, you need to explicitly configure TILECFG using tileconfig_t.
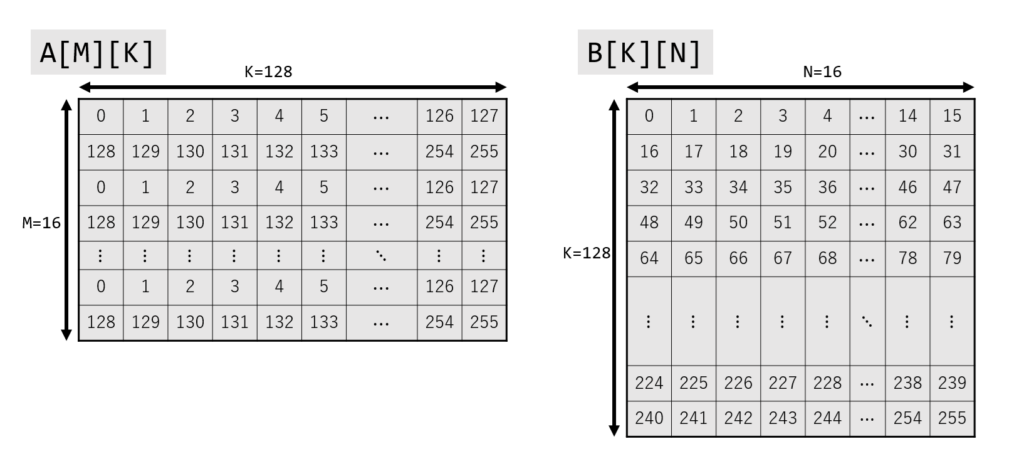
The sample code calculates an unsigned INT8 matrix multiplication: computing an INT32 matrix C[M][N] from an INT8 matrix A[M][K] and an INT8 matrix B[K][N]. We set M = 16, K = 128, and N = 16. Since a TILEDATA register can handle up to 16 rows x 64 bytes, we split matrices A and B into two parts each for the calculation.
Let’s walk through the necessary operations.
Include Header
AMX intrinsics, like AVX, can be accessed by including immintrin.h.
#include <immintrin.h>Enable AMX
AMX may be disabled by default, so we enable it using the arch_prctl system call.
if (syscall(SYS_arch_prctl, ARCH_REQ_XCOMP_PERM, XFEATURE_XTILEDATA) < 0) {
printf("Failed to enable XFEATURE_XTILEDATA\n");
exit(-1);
}Initialize Matrices A, B, and C
Prepare A, B, and C, and initialize A and B with some values. Note that C is of type uint32_t. (The types of A and B are uint8_t, so we use the remainder when divided by 256, which causes them to wrap around to 0.)
std::array<std::uint8_t, M * K> A;
std::array<std::uint8_t, K * N> B;
std::array<std::uint32_t, M * N> C;
for (int i = 0; i < M; i++) {
for (int j = 0; j < K; j++) {
A[(i * K) + j] = static_cast<std::uint8_t>(((i * K) + j) % 256);
}
}
for (int i = 0; i < K; i++) {
for (int j = 0; j < N; j++) {
B[(i * N) + j] = static_cast<std::uint8_t>(((i * N) + j) % 256);
}
}
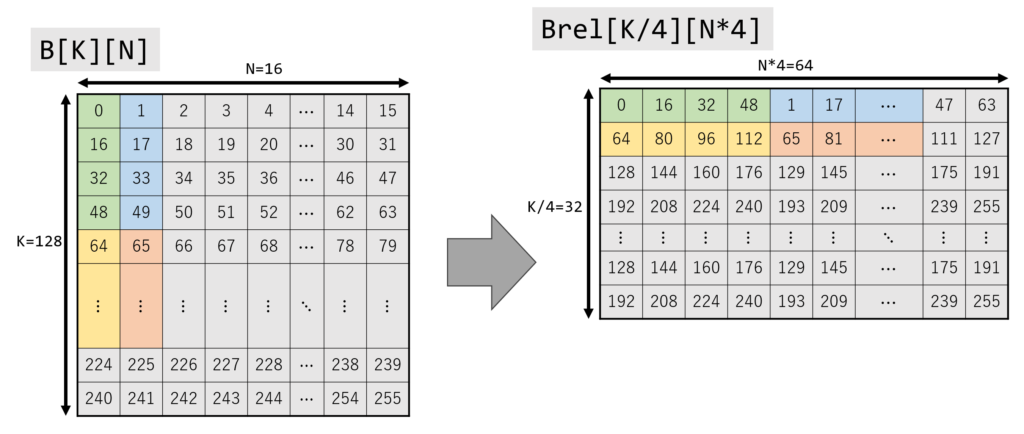
Change Memory Layout of B
Reorder the data in B to match the AMX layout. Note that the number of rows and columns of Brel changes. The number of rows in Brel will be the same as the number of rows in B divided by 4. (In this case, B has 128 rows, so Brel will have 32 rows).
std::array<std::uint8_t, (K / 4) * (N * 4)> Brel;
for (int i = 0; i < K; i += 4) {
for (int j = 0; j < N; j++) {
Brel[(i * N) + (j * 4) + 0] = B[((i + 0) * N) + j];
Brel[(i * N) + (j * 4) + 1] = B[((i + 1) * N) + j];
Brel[(i * N) + (j * 4) + 2] = B[((i + 2) * N) + j];
Brel[(i * N) + (j * 4) + 3] = B[((i + 3) * N) + j];
}
}
Tile Configuration
Initialize the TILEDATA registers. The arguments to __tile1024i specify the matrix size in the order of rows, colb. In the sample code, all are set to rows = 16, colb = 64.
Each corresponds to a tile in the diagram below.
__tile1024i tile_a1 = {M, K / 2}; // {16, 64}
__tile1024i tile_a2 = {M, K / 2}; // {16, 64}
__tile1024i tile_b1 = {K / 4 / 2, N * 4}; // {16, 64}
__tile1024i tile_b2 = {K / 4 / 2, N * 4}; // {16, 64}
__tile1024i tile_c = {M, N * 4}; // {16, 64}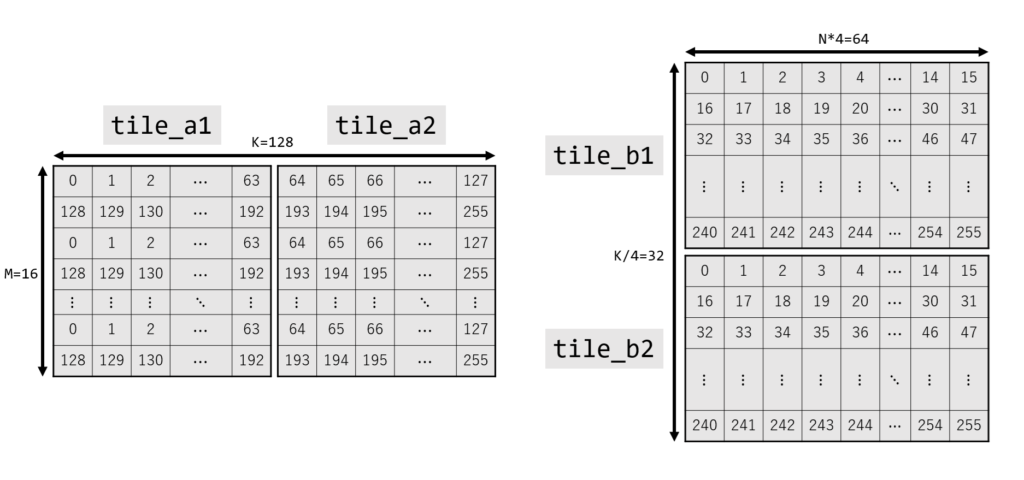
Tile Load
Load matrices A and Brel into TILEDATA registers. The strides are K [bytes/row] and N*4 [bytes/row] respectively, and the type is uint8_t, so the strides are K and N*4.
__tile_loadd(&tile_a1, A.data(), K);
__tile_loadd(&tile_a2, A.data() + (K / 2), K);
__tile_loadd(&tile_b1, Brel.data(), N * 4);
__tile_loadd(&tile_b2, Brel.data() + ((K / 4) / 2 * N * 4), N * 4);TMUL Operation
Calculate the matrix product. Since this is unsigned INT8, we use dpbuud. TILEDATA registers are implicitly zero-filled in their initial state, so there is no need to initialize tile_c with __tile_zero.
__tile_dpbuud(&tile_c, tile_a1, tile_b1);
__tile_dpbuud(&tile_c, tile_a2, tile_b2);Tile Store
Store the calculation result into the memory for C. Each row consists of N*4-byte integers, for a total of N*4 bytes, so we specify N4 for the stride.
__tile_stored(C.data(), N * 4, tile_c);Tile Release
Reset TILECFG and TILEDATA to their initial state.
_tile_release();Full Sample Code
Here is the full sample code used in the explanation above.
Comments in the code indicate the corresponding section titles in this article.
Sample Code (__tile1024i ver.)
#include <immintrin.h>
#include <sys/syscall.h>
#include <unistd.h>
#include <array>
#include <cstdint>
#include <cstdio>
constexpr int ARCH_REQ_XCOMP_PERM = 0x1023;
constexpr int XFEATURE_XTILEDATA = 18;
constexpr std::uint8_t M = 16;
constexpr std::uint8_t K = 128;
constexpr std::uint8_t N = 16;
int main() {
// Enable AMX
if (syscall(SYS_arch_prctl, ARCH_REQ_XCOMP_PERM, XFEATURE_XTILEDATA) < 0) {
std::printf("Failed to enable XFEATURE_XTILEDATA\n");
exit(-1);
}
// Initialize matrices A, B, and C
std::array<std::uint8_t, M * K> A;
std::array<std::uint8_t, K * N> B;
std::array<std::uint32_t, M * N> C;
for (int i = 0; i < M; i++) {
for (int j = 0; j < K; j++) {
A[(i * K) + j] = static_cast<std::uint8_t>(((i * K) + j) % 256);
}
}
for (int i = 0; i < K; i++) {
for (int j = 0; j < N; j++) {
B[(i * N) + j] = static_cast<std::uint8_t>(((i * N) + j) % 256);
}
}
// Change memory layout of B
std::array<std::uint8_t, (K / 4) * (N * 4)> Brel;
for (int i = 0; i < K; i += 4) {
for (int j = 0; j < N; j++) {
Brel[(i * N) + (j * 4) + 0] = B[((i + 0) * N) + j];
Brel[(i * N) + (j * 4) + 1] = B[((i + 1) * N) + j];
Brel[(i * N) + (j * 4) + 2] = B[((i + 2) * N) + j];
Brel[(i * N) + (j * 4) + 3] = B[((i + 3) * N) + j];
}
}
// Tile Configuration
__tile1024i tile_a1 = {M, K / 2}; // {16, 64}
__tile1024i tile_a2 = {M, K / 2}; // {16, 64}
__tile1024i tile_b1 = {K / 4 / 2, N * 4}; // {16, 64}
__tile1024i tile_b2 = {K / 4 / 2, N * 4}; // {16, 64}
__tile1024i tile_c = {M, N * 4}; // {16, 64}
// Tile Load
__tile_loadd(&tile_a1, A.data(), K);
__tile_loadd(&tile_a2, A.data() + (K / 2), K);
__tile_loadd(&tile_b1, Brel.data(), N * 4);
__tile_loadd(&tile_b2, Brel.data() + ((K / 4) / 2 * N * 4), N * 4);
// TMUL Operation
__tile_dpbuud(&tile_c, tile_a1, tile_b1);
__tile_dpbuud(&tile_c, tile_a2, tile_b2);
// Tile Store
__tile_stored(C.data(), N * 4, tile_c);
// Tile Release
_tile_release();
for (int i = 0; i < M; i++) {
for (int j = 0; j < N; j++) {
std::printf("%d ", C[(i * N) + j]);
}
std::printf("\n");
}
}If you are using GCC or want to manage registers yourself, you can also write it as follows.
The call to _tile_loadconfig is added, and the arguments that specified the __tile1024i struct are now replaced with register numbers.
Note that the function names change from __tile_* to _tile_*, and the order of arguments for _tile_stored has changed.
Full Code (GCC-specific parts are commented with // GCC specific)
#include <immintrin.h>
#include <sys/syscall.h>
#include <unistd.h>
#include <array>
#include <cstdint>
#include <cstdio>
constexpr int ARCH_REQ_XCOMP_PERM = 0x1023;
constexpr int XFEATURE_XTILEDATA = 18;
constexpr std::uint8_t M = 16;
constexpr std::uint8_t K = 128;
constexpr std::uint8_t N = 16;
// GCC specific: Define struct for TILECFG
struct tileconfig_t
{
std::uint8_t palette_id;
std::uint8_t startRow;
std::uint8_t reserved_0[14];
std::uint16_t colb[16];
std::uint8_t rows[16];
};
int main() {
if (syscall(SYS_arch_prctl, ARCH_REQ_XCOMP_PERM, XFEATURE_XTILEDATA) < 0) {
std::printf("Failed to enable XFEATURE_XTILEDATA\n");
exit(-1);
}
std::array<std::uint8_t, M * K> A;
std::array<std::uint8_t, K * N> B;
std::array<std::uint32_t, M * N> C;
for (int i = 0; i < M; i++) {
for (int j = 0; j < K; j++) {
A[(i * K) + j] = static_cast<std::uint8_t>(((i * K) + j) % 256);
}
}
for (int i = 0; i < K; i++) {
for (int j = 0; j < N; j++) {
B[(i * N) + j] = static_cast<std::uint8_t>(((i * N) + j) % 256);
}
}
std::array<std::uint8_t, (K / 4) * (N * 4)> Brel;
for (int i = 0; i < K; i += 4) {
for (int j = 0; j < N; j++) {
Brel[(i * N) + (j * 4) + 0] = B[((i + 0) * N) + j];
Brel[(i * N) + (j * 4) + 1] = B[((i + 1) * N) + j];
Brel[(i * N) + (j * 4) + 2] = B[((i + 2) * N) + j];
Brel[(i * N) + (j * 4) + 3] = B[((i + 3) * N) + j];
}
}
// GCC specific: Configure TILECFG
const tileconfig_t config = {
.palette_id = 1,
.startRow = 0,
.colb = {K / 2, K / 2, N * 4, N * 4, N * 4}, // {64, 64, 64, 64, 64}
.rows = {M, M, K / 4 / 2, K / 4 / 2, M}, // {16, 16, 16, 16, 16}
};
_tile_loadconfig(&config);
// GCC specific: Specify TILEDATA location by tile number
_tile_loadd(0, A.data(), K);
_tile_loadd(1, A.data() + (K / 2), K);
_tile_loadd(2, Brel.data(), N * 4);
_tile_loadd(3, Brel.data() + (K / 4 / 2 * N * 4), N * 4);
_tile_dpbuud(4, 0, 2);
_tile_dpbuud(4, 1, 3);
_tile_stored(4, C.data(), N * 4);
_tile_release();
for (int i = 0; i < M; i++) {
for (int j = 0; j < N; j++) {
std::printf("%d ", C[(i * N) + j]);
}
std::printf("\n");
}
}Compilation/Execution
Compiling and running the above sample code will calculate and output the matrix product. Since it contains AMX instructions, a compatible compiler and the compile options -mamx-tile -mamx-int8 are required.
Even on CPUs that do not support AMX instructions, you can emulate them with the Intel® Software Development Emulator. When running, specify sde64 -spr -- <exec file>. (spr = SaPphire Rapids)
You can check if your CPU supports AMX using the lscpu command or the cpuid instruction.
[Reference] C++ program to check AMX support status
#include <cstdio>
#include <cpuid.h>
int main() {
unsigned int eax_07_0, ebx_07_0, ecx_07_0, edx_07_0;
unsigned int eax_07_1, ebx_07_1, ecx_07_1, edx_07_1;
unsigned int eax_0d_0, ebx_0d_0, ecx_0d_0, edx_0d_0;
unsigned int eax_1d_0, ebx_1d_0, ecx_1d_0, edx_1d_0;
unsigned int eax_1d_1, ebx_1d_1, ecx_1d_1, edx_1d_1;
unsigned int eax_1e_0, ebx_1e_0, ecx_1e_0, edx_1e_0;
__cpuid_count(0x07, 0, eax_07_0, ebx_07_0, ecx_07_0, edx_07_0);
__cpuid_count(0x07, 1, eax_07_1, ebx_07_1, ecx_07_1, edx_07_1);
__cpuid_count(0x0d, 0, eax_0d_0, ebx_0d_0, ecx_0d_0, edx_0d_0);
__cpuid_count(0x1d, 0, eax_1d_0, ebx_1d_0, ecx_1d_0, edx_1d_0);
__cpuid_count(0x1d, 1, eax_1d_1, ebx_1d_1, ecx_1d_1, edx_1d_1);
__cpuid_count(0x1e, 0, eax_1e_0, ebx_1e_0, ecx_1e_0, edx_1e_0);
std::printf("TILECFG state: %d\n", eax_0d_0>>17&1);
std::printf("TILEDATA state: %d\n", eax_0d_0>>18&1);
std::printf("AMX-BF16: %d\n", edx_07_0>>22&1);
std::printf("AMX-TILE: %d\n", edx_07_0>>24&1);
std::printf("AMX-INT8: %d\n", edx_07_0>>25&1);
std::printf("AMX-FP16: %d\n", eax_07_1>>21&1);
std::printf("AMX-COMPLEX: %d\n", edx_07_1>> 8&1);
std::printf("max_palette: %d\n", eax_1d_0);
std::printf("total_tile_bytes: %d\n", eax_1d_1 &0xffff);
std::printf("bytes_per_tile: %d\n", eax_1d_1>>16&0xffff);
std::printf("bytes_per_row: %d\n", ebx_1d_1 &0xffff);
std::printf("max_names: %d\n", ebx_1d_1>>16&0xffff);
std::printf("max_rows: %d\n", ecx_1d_1 &0xffff);
std::printf("tmul_maxk: %d\n", ebx_1e_0 &0xff);
std::printf("tmul_maxn: %d\n", ebx_1e_0>> 8&0xffff);
return 0;
}# CPU without AMX support
TILECFG state: 0
TILEDATA state: 0
AMX-BF16: 0
AMX-TILE: 0
AMX-INT8: 0
AMX-FP16: 0
AMX-COMPLEX: 0
max_palette: 0
total_tile_bytes: 0
bytes_per_tile: 0
bytes_per_row: 0
max_names: 0
max_rows: 0
tmul_maxk: 0
tmul_maxn: 0
# CPU with AMX support (Sapphire Rapids)
TILECFG state: 1
TILEDATA state: 1
AMX-BF16: 1
AMX-TILE: 1
AMX-INT8: 1
AMX-FP16: 0 <=== This would be 1 on Granite Rapids
AMX-COMPLEX: 0
max_palette: 1
total_tile_bytes: 8192
bytes_per_tile: 1024
bytes_per_row: 64
max_names: 8
max_rows: 16
tmul_maxk: 16
tmul_maxn: 64Performance Verification
We will now verify how much performance improvement AMX provides over AVX512 using OpenBLAS v0.3.29.
The measurement environment is as follows:
| Environment | Configuration |
|---|---|
| OS | Red Hat Enterprise Linux 9.2 |
| CPU | Intel(R) Xeon(R) Platinum 8480CL x2 (56 Core x 2, HT-disabled) |
| Memory | 512GB (DDR5 32GB x 16) |
| Compiler | g++ 14.1.0 |
| Compile Options | -O3 -march=native |
The measurement conditions are the following four types:
- AVX512_BF16 / 1-Thread
- AVX512_BF16 / 112-Threads
- AMX (BF16) / 1-Thread
- AMX (BF16) / 112-Threads
Under each condition, we measured the execution time of calculating an N*N matrix product of BF16 type using cblas_sbgemm. OpenBLAS was compiled separately for each condition. Since there was no flag to disable AMX, we specified Cooper Lake, a target architecture that does not support AMX.
- AVX512_BF16:
TARGET=COOPERLAKE BUILD_BFLOAT16=1- Kernel function:
sbgemm_kernel_16x4_cooperlake.c
- Kernel function:
- AMX (BF16):
TARGET=SAPPHIRERAPIDS BUILD_BFLOAT16=1- Kernel function:
sbgemm_kernel_16x16_spr.c
- Kernel function:
The measurement results are shown in the following table.
Execution time ([ms], average of 5 runs) for each implementation vs. matrix size N
| N | AMX/1-thread | AVX512/1-thread | AMX/112-threads | AVX512/112-threads |
|---|---|---|---|---|
| 512 | 0.8 | 3.9 | 0.9 | 1.1 |
| 1024 | 3.1 | 28.1 | 1.6 | 1.9 |
| 1536 | 9.0 | 93.6 | 2.3 | 2.6 |
| 2048 | 19.8 | 221.1 | 2.9 | 4.2 |
| 2560 | 37.2 | 442.5 | 6.3 | 6.4 |
| 3072 | 62.5 | 742.7 | 4.5 | 9.4 |
| 3584 | 98.1 | 1180.2 | 7.3 | 13.7 |
| 4096 | 150.4 | 1763.3 | 10.5 | 20.6 |
The following graph visualizes the table above. The results are normalized to the AMX 1-Thread performance.
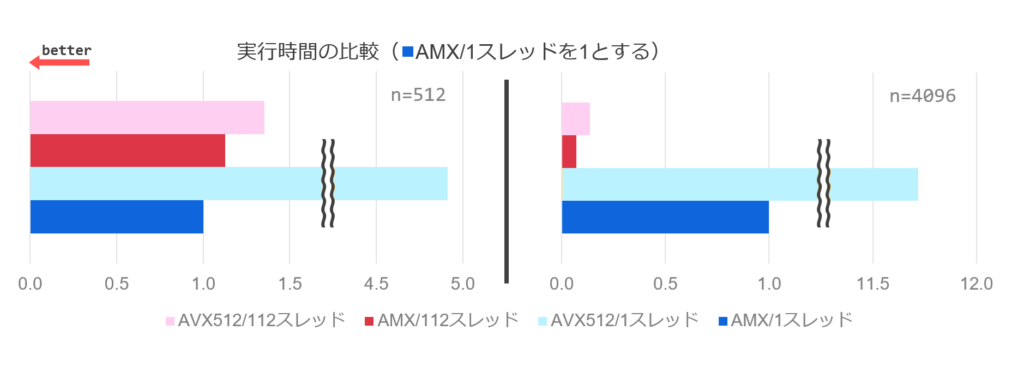
In single-threaded performance, AMX (blue) is up to about 11.7 times faster (at N = 4096) than AVX512 (yellow). In multi-threaded performance, AMX (red) also outperforms AVX512 (green), but the performance scaling is less pronounced than in the single-threaded case. Further investigation is needed, but this is likely influenced by various optimizations and the operating frequency of the arithmetic units themselves.
Conclusion
In this article, we provided a detailed analysis of AMX, from its instruction set to a performance comparison with AVX.
In the next article, we will introduce optimizations for extracting the full performance of AMX! Stay tuned!
References
- Intel® Intrinsics Guide, https://www.intel.com/content/www/us/en/docs/intrinsics-guide/index.html
- Intel® Architecture Instruction Set Extensions Programming Reference, https://www.intel.com/content/www/us/en/content-details/843860/intel-architecture-instruction-set-extensions-programming-reference.html
- Intel® 64 and IA-32 Architectures Software Developer’s Manual, https://www.intel.co.jp/content/www/jp/ja/content-details/782158/intel-64-and-ia-32-architectures-software-developer-s-manual-combined-volumes-1-2a-2b-2c-2d-3a-3b-3c-3d-and-4.html
- Intel® 64 and IA-32 Architectures Optimization Reference Manual: Volume 1, https://www.intel.co.jp/content/www/jp/ja/content-details/671488/intel-64-and-ia-32-architectures-optimization-reference-manual-volume-1.html