
* This blog post is an English translation of an article originally published in Japanese on April 6, 2025.
On April 6, 2025, Llama 4 was released. Llama 4 is a multimodal model capable of image and video input, with a lineup consisting of the 109B parameter Llama 4 Scout, the 400B parameter Llama 4 Maverick, and the 2000B parameter Llama 4 Behemoth. Currently, two of these, Scout and Maverick, have been released.
According to the press release, Scout can operate with a long context of up to 10 million tokens and can process 20 hours of video input. For LLMs handling such large amounts of data, running them on-premise, rather than relying on API access as before, becomes a viable option. Therefore, this time, we will perform operational checks and profiling assuming an on-premise deployment of Llama 4 Scout.
Llama 4 Operational Check
First, we will perform an operational check using the transformers library, following the official procedures. This procedure requires four H100 GPUs to run the model directly at FP16 precision without quantization.
First, since Llama 4 is a gated model requiring authentication for access, we apply for access rights from https://huggingface.co/meta-llama/Llama-4-Scout-17B-16E-Instruct. In our case, authentication was granted in about 10 minutes.
Meanwhile, we set up the environment. To run the official script correctly, several additional libraries need to be installed besides transformers as listed in the manual.
We create a requirements.txt file with the following content:
pillow
transformers
accelerate
huggingface_hub[hf_xet]
torch
torchvisionWe install the libraries using this requirements.txt file.
uv venv -p 3.11
. .venv/bin/activate
uv pip install -r requirements.txtThe following versions were installed this time:
Installed 42 packages in 3.06s
+ accelerate==1.6.0
+ certifi==2025.1.31
+ charset-normalizer==3.4.1
+ filelock==3.18.0
+ fsspec==2025.3.2
+ hf-xet==1.0.0
+ huggingface-hub==0.30.1
+ idna==3.10
+ jinja2==3.1.6
+ markupsafe==3.0.2
+ mpmath==1.3.0
+ networkx==3.4.2
+ numpy==2.2.4
+ nvidia-cublas-cu12==12.4.5.8
+ nvidia-cuda-cupti-cu12==12.4.127
+ nvidia-cuda-nvrtc-cu12==12.4.127
+ nvidia-cuda-runtime-cu12==12.4.127
+ nvidia-cudnn-cu12==9.1.0.70
+ nvidia-cufft-cu12==11.2.1.3
+ nvidia-curand-cu12==10.3.5.147
+ nvidia-cusolver-cu12==11.6.1.9
+ nvidia-cusparse-cu12==12.3.1.170
+ nvidia-cusparselt-cu12==0.6.2
+ nvidia-nccl-cu12==2.21.5
+ nvidia-nvjitlink-cu12==12.4.127
+ nvidia-nvtx-cu12==12.4.127
+ packaging==24.2
+ pillow==11.1.0
+ psutil==7.0.0
+ pyyaml==6.0.2
+ regex==2024.11.6
+ requests==2.32.3
+ safetensors==0.5.3
+ sympy==1.13.1
+ tokenizers==0.21.1
+ torch==2.6.0
+ torchvision==0.21.0
+ tqdm==4.67.1
+ transformers==4.51.0
+ triton==3.2.0
+ typing-extensions==4.13.1
+ urllib3==2.3.0Next, after confirming that access rights have been obtained, we download the model using huggingface-cli. Create an access token from https://huggingface.co/settings/tokens and log in from the CLI.
huggingface-cli loginThe model can be downloaded with the following command:
huggingface-cli download meta-llama/Llama-4-Scout-17B-16E-InstructCopy the official script to the current directory and change the model name.
Currently, there is an incompatibility with the flex_attention library causing errors, so we will comment out the attn_implementation specification here.
The modified script is shown below:
from transformers import AutoProcessor, Llama4ForConditionalGeneration
import torch
# model_id = "meta-llama/Llama-4-Maverick-17B-128E-Instruct"
model_id = "meta-llama/Llama-4-Scout-17B-16E-Instruct"
processor = AutoProcessor.from_pretrained(model_id)
model = Llama4ForConditionalGeneration.from_pretrained(
model_id,
# attn_implementation="flex_attention",
device_map="auto",
torch_dtype=torch.bfloat16,
)
url1 = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/0052a70beed5bf71b92610a43a52df6d286cd5f3/diffusers/rabbit.jpg"
url2 = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/datasets/cat_style_layout.png"
messages = [
{
"role": "user",
"content": [
{"type": "image", "url": url1},
{"type": "image", "url": url2},
{"type": "text", "text": "Can you describe how these two images are similar, and how they differ?"},
]
},
]
inputs = processor.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt",
).to(model.device)
outputs = model.generate(
**inputs,
max_new_tokens=256,
)
response = processor.batch_decode(outputs[:, inputs["input_ids"].shape[-1]:])[0]
print(response)
print(outputs[0])Run with 4 GPUs specified.
CUDA_VISIBLE_DEVICES=0,1,2,3 python llama4.pyIt completed successfully, and the following results were obtained. As instructed, the model correctly explained the similarities and differences between the two images.
The two images depict anthropomorphic animals, a rabbit and a cat, dressed in similar attire. The rabbit is standing on a dirt path with flowers and houses in the background, while the cat is sitting on a stone path surrounded by greenery.
**Similarities:**
* Both characters are wearing blue jackets, brown vests, and bow ties.
* They have similar facial expressions, with large eyes and endearing features.
* The backgrounds of both images feature natural settings, including paths, flowers, and houses.
**Differences:**
* **Species:** The most obvious difference is that one character is a rabbit and the other is a cat.
* **Posture:** The rabbit is standing upright on two legs, while the cat is sitting on all fours.
* **Background:** Although both backgrounds feature natural settings, they differ in terms of composition. The rabbit's background includes a house and mountains, whereas the cat's background features a more intimate garden scene with a wooden fence.
* **Coloring:** The rabbit has lighter-colored fur than the cat, which has darker orange tones.
Overall, while the two images share some similarities in terms of character design and setting, they also exhibit distinct differences in terms of species, posture, and background composition.Profiling
Next, we will perform profiling on this script using NVIDIA Nsight Systems (nsys). Using the nsys profile command generates a .nsys-rep file with the profiling results.
CUDA_VISIBLE_DEVICES=0,1,2,3 nsys profile python llama4.pyOpening the generated .nsys-rep file with the NVIDIA Nsight Systems GUI yields the following profiling results.

Overall, we can observe that GPU0 starts working, followed by GPU1, GPU2, and GPU3 in sequence. This indicates that pipeline parallelism is used as the parallelization method, meaning it operates sequentially layer by layer.
Let’s look at the profile results in detail. The parts shown in green are where the model weights are being loaded. After that, we can see the prefill stage, which processes all input tokens in parallel, followed by the decode stage, which generates tokens sequentially one by one.

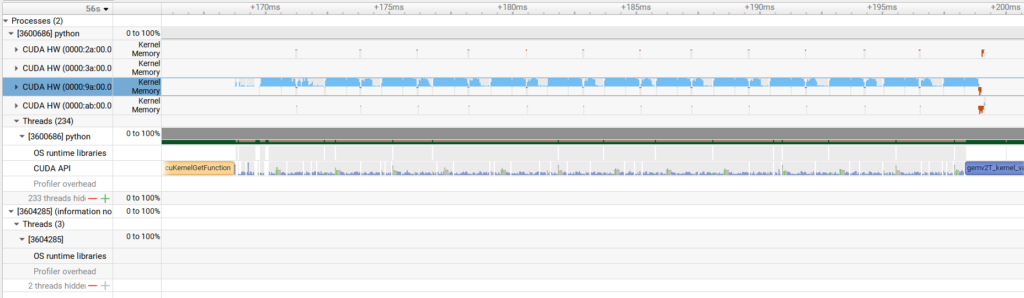
Zooming into the prefill stage down to the layer level, we can see that kernel execution is happening for the most part. At least on a single GPU, it appears to be running efficiently through appropriate PyTorch function calls.
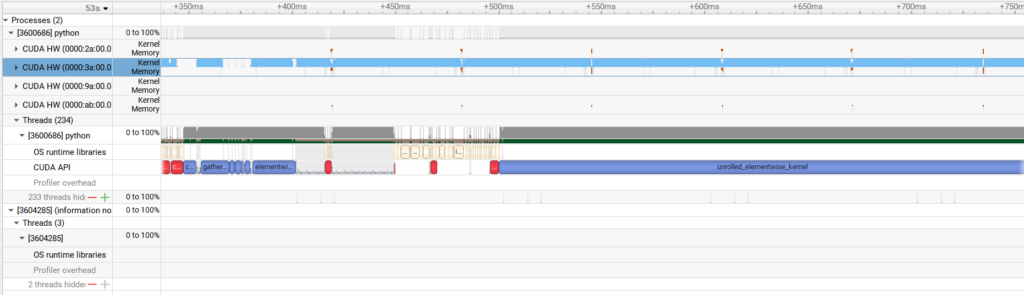
Compared to this, the decode stage has portions where the GPU is not being used. In addition to the relatively small computation amount for per-token inference, the adoption of the MoE (Mixture of Experts) architecture in Llama 4 further reduces computation. This suggests that GPU computational resources are not being fully utilized.
This measurement was taken with flex_attention turned off due to an error, but if the ChunkedAttention used in Llama 4 works correctly, we can expect improvements in execution speed and profile results.
However, not limited to Llama 4, the default settings of the transformers library are generally not optimized for parallel performance. When deploying Llama 4 as an inference service, it is advisable to use other libraries like vLLM.
Summary
This time, we performed an operational check and profiling of Llama 4. The latest high-performance LLMs are becoming increasingly large and complex. We found that various ingenuities, including parallelization strategies, are necessary when considering running them locally. Furthermore, as evidenced by the need to modify the script for operational checks, the procedures for running them easily and quickly are not well-established, which could be a barrier to local LLM utilization. We intend to continue investigating and publishing information on the training and inference of LLMs, including Llama 4, to contribute to the popularization of local LLMs.
[Ad] Optimize your AI model performance with our Performance Engineering Platform – Fixstars AIBooster.
Fixstars AIBooster for GPU servers gathers runtime data, identifies bottlenecks, and enhances performance with actionable insights.
Learn more: Fixstars AIBooster Product Page